Análise de requisitos: identificação do propósito do banco de dados
Compreender o propósito do seu banco de dados informará suas escolhas ao longo do processo de design. Certifique-se de considerar o banco de dados sob todas as perspectivas. Por exemplo, se você estivesse criando um banco de dados para uma biblioteca pública, deveria considerar as maneiras pelas quais tanto os usuários quanto os bibliotecários precisariam acessar os dados.
Aqui estão algumas maneiras de coletar informações antes de criar o banco de dados:
- Entrevistar as pessoas que vão usá-lo
- Analisar formulários comerciais, como faturas, planilhas de horários e pesquisas
- Examinar quaisquer sistemas de dados existentes (incluindo arquivos físicos e digitais)
Comece coletando todos os dados existentes que serão incluídos no banco de dados. Em seguida, liste os tipos de dados que deseja armazenar e as entidades, ou pessoas, coisas, locais e eventos que esses dados descrevem, desta forma:
Clientes
- Nome
- Endereço
- Cidade, Estado, CEP
- Endereço de e-mail
Produtos
- Nome
- Preço
- Quantidade em estoque
- Quantidade encomendada
Pedidos
- ID do pedido
- Representante de vendas
- Data
- Produto(s)
- Quantidade
- Preço
- Total
Essas informações farão parte posteriormente do dicionário de dados, que descreve as tabelas e os campos do banco de dados. Certifique-se de dividir as informações nos menores pedaços úteis. Por exemplo, considere separar o endereço do país para que você possa filtrar os indivíduos pelo país de residência mais tarde. Além disso, evite colocar o mesmo ponto de dados em mais de uma tabela, o que adiciona complexidade desnecessária.
Depois de saber que tipos de dados o banco de dados incluirá, de onde esses dados vêm e como serão usados, você estará pronto para começar a planejar o banco de dados propriamente dito.
Estrutura do banco de dados: os blocos de construção de um banco de dados
A próxima etapa é definir uma representação visual do seu banco de dados. Para fazer isso, você precisa entender exatamente como os bancos de dados relacionais são estruturados.
Em um banco de dados, os dados relacionados são agrupados em tabelas, cada uma consistindo de linhas (também chamadas de tuplas) e colunas, como em uma planilha.
To convert your lists of data into tables, start by creating a table for each type of entity, such as products, sales, customers, and orders. Here’s an example:
Cada linha de uma tabela é chamada de registro. Os registros incluem dados sobre algo ou alguém, como um cliente específico. Por outro lado, as colunas (também conhecidas como campos ou atributos) contêm um único tipo de informação que aparece em cada registro, como os endereços de todos os clientes listados na tabela.
| Nome | Sobrenome | Idade | CEP |
|---|
| Roger | Williams | 43 | 34760 |
| Jerrica | Jorgensen | 32 | 97453 |
| Samantha | Hopkins | 56 | 64829 |
Para manter os dados consistentes de um registro para outro, atribua o tipo de dados apropriado a cada coluna. Os tipos de dados comuns incluem:
- CHAR - um comprimento específico de texto
- VARCHAR - texto de comprimentos variáveis
- TEXT - grandes quantidades de texto
- INT - número inteiro positivo ou negativo
- FLOAT, DOUBLE - também podem armazenar números de ponto flutuante
- BLOB - dados binários
Alguns sistemas de gerenciamento de banco de dados também oferecem o tipo de dados Autonumber, que gera automaticamente um número exclusivo em cada linha.
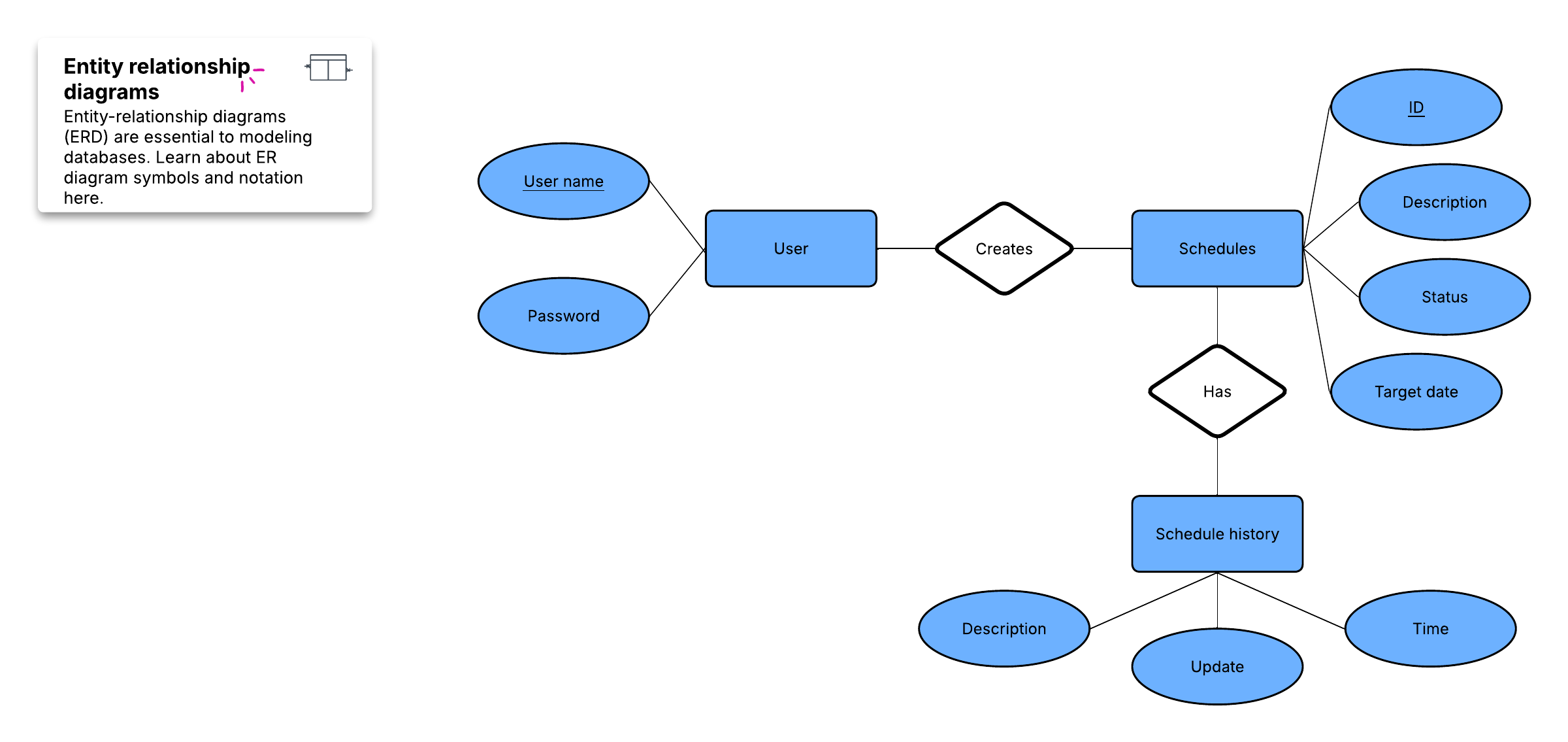
Para fins de criação de uma visão geral visual do banco de dados, conhecido como diagrama de entidade-relacionamento, você não incluirá as tabelas reais. Em vez disso, cada tabela torna-se uma caixa no diagrama. O título de cada caixa deve indicar o que os dados nessa tabela descrevem, enquanto os atributos são listados abaixo, assim:

Por fim, você deve decidir qual atributo ou atributos servirão como chave primária para cada tabela, se houver. Uma chave primária (PK) é um identificador exclusivo para uma determinada entidade, o que significa que você poderia identificar um cliente exato mesmo se conhecesse apenas esse valor.
Os atributos escolhidos como chaves primárias devem ser exclusivos, imutáveis e sempre presentes (nunca NULL ou vazios). Por esse motivo, números de pedidos e nomes de usuário são boas chaves primárias, enquanto números de telefone ou endereços residenciais não são. Você também pode usar vários campos em conjunto como chave primária (isso é conhecido como chave composta).
Quando chegar a hora de criar o banco de dados real, você colocará a estrutura de dados lógica e a estrutura de dados física na linguagem de definição de dados compatível com o seu sistema de gerenciamento de banco de dados. Nesse ponto, você também deve estimar o tamanho do banco de dados para ter certeza de obter o nível de desempenho e o espaço de armazenamento necessários.
Criação de relacionamentos entre entidades
Com as tabelas do seu banco de dados agora convertidas em tabelas, você está pronto para analisar os relacionamentos entre elas. A cardinalidade refere-se à quantidade de elementos que interagem entre duas tabelas relacionadas. Identificar a cardinalidade ajuda a garantir que você dividiu os dados em tabelas da maneira mais eficiente.
Cada entidade pode potencialmente ter um relacionamento com todas as outras, mas esses relacionamentos são normalmente de um dos três tipos:
Relacionamentos um para um
Quando há apenas uma instância da Entidade A para cada instância da Entidade B, diz-se que elas têm um relacionamento um para um (geralmente escrito como 1:1). Você pode indicar esse tipo de relacionamento em um diagrama ER com uma linha com um traço em cada extremidade:

A menos que você tenha um bom motivo para não fazer isso, um relacionamento 1:1 geralmente indica que seria melhor combinar os dados das duas tabelas em uma única tabela.
No entanto, você pode querer criar tabelas com um relacionamento 1:1 sob um conjunto específico de circunstâncias. Se você tiver um campo com dados opcionais, como "descrição", que está em branco para muitos dos registros, poderá mover todas as descrições para sua própria tabela, eliminando o espaço vazio e melhorando o desempenho do banco de dados.
Para garantir que os dados correspondam corretamente, você terá que incluir pelo menos uma coluna idêntica em cada tabela, provavelmente a chave primária.
Relacionamentos um para muitos
Esses relacionamentos ocorrem quando um registro em uma tabela está associado a várias entradas em outra. Por exemplo, um único cliente pode ter feito muitos pedidos, ou um usuário pode ter vários livros retirados da biblioteca ao mesmo tempo. Os relacionamentos um para muitos (1:M) são indicados com o que é chamado de "notação de pé de galinha", como neste exemplo:

Para implementar um relacionamento 1:M ao configurar um banco de dados, basta adicionar la chave primária do lado "um" do relacionamento como um atributo na outra tabela. Quando uma chave primária é listada em outra tabela dessa maneira, ela é chamada de chave estrangeira. A tabela no lado "1" do relacionamento é considerada uma tabela pai para a tabela filho do outro lado.
Relacionamentos muitos para muitos
Quando várias entidades de uma tabela podem ser associadas a várias entidades em outra tabela, diz-se que elas têm um relacionamento muitos para muitos (M:N). Isso pode acontecer no caso de alunos e turmas, já que um aluno pode fazer várias turmas e uma turma pode ter muitos alunos.
Em um diagrama ER, esses relacionamentos são representados com estas linhas:

Infelizmente, não é possível implementar diretamente esse tipo de relacionamento em um banco de dados. Em vez disso, você precisa dividi-lo em dois relacionamentos um para muitos.
Para fazer isso, crie uma nova entidade entre essas duas tabelas. Se o relacionamento M:N existir entre vendas e produtos, você poderá chamar essa nova entidade de "produtos_vendidos", pois ela mostraria o conteúdo de cada venda. Tanto a tabela de vendas quanto a de produtos teriam um relacionamento 1:M com produtos_vendidos. Esse tipo de entidade intermediária é chamado de tabela de ligação, entidade associativa ou tabela de junção em vários modelos.
Cada registro na tabela de ligação corresponderia a duas das entidades nas tabelas vizinhas (pode incluir informações complementares também). Por exemplo, uma tabela de ligação entre alunos e turmas poderia ser assim:

Obrigatório ou não?
Outra maneira de analisar relacionamentos é considerar qual lado do relacionamento deve existir para que o outro exista. O lado não obrigatório pode ser marcado com um círculo na linha onde estaria um traço. Por exemplo, um país precisa existir para ter um representante nas Nações Unidas, mas o oposto não é verdadeiro:

Duas entidades podem ser mutuamente dependentes (uma não poderia existir sem a outra).
Relacionamentos recursivos
Às vezes, uma tabela aponta de volta para si mesma. Por exemplo, uma tabela de funcionários pode ter um atributo "gerente" que se refere a outro indivíduo nessa mesma tabela. Isso é chamado de relacionamento recursivo.
Relacionamentos redundantes
Um relacionamento redundante é aquele que é expresso mais de uma vez. Normalmente, você pode remover um dos relacionamentos sem perder nenhuma informação importante. Por exemplo, se uma entidade "alunos" tem um relacionamento direto com outra chamada "professores", mas também tem um relacionamento com professores indiretamente por meio de "turmas", você deve remover o relacionamento entre "alunos" e "professores". É melhor excluir esse relacionamento porque a única maneira de os alunos serem atribuídos aos professores é por meio das turmas.
Normalização de banco de dados
Depois de ter um design preliminar para o seu banco de dados, você pode aplicar regras de normalização para garantir que as tabelas estejam estruturadas corretamente. Pense nessas regras como os padrões do setor.
Dito isso, nem todos os bancos de dados são bons candidatos para normalização. Em geral, os bancos de dados de processamento de transações on-line (OLTP, na sigla em inglês), nos quais os usuários estão preocupados em criar, ler, atualizar e excluir registros, devem ser normalizados.
Bancos de dados de processamento analítico on-line (OLAP) que favorecem a análise e os relatórios podem se sair melhor com um certo grau de desnormalização, já que a ênfase está na velocidade do cálculo. Eles incluem aplicativos de suporte à decisão nos quais os dados precisam ser analisados rapidamente, mas não alterados.
Cada forma, ou nível de normalização, inclui as regras associadas às formas inferiores.
Primeira forma normal
A primeira forma normal (abreviada como 1FN) especifica que cada célula na tabela pode ter apenas um valor, nunca uma lista de valores, portanto, uma tabela como esta não está em conformidade:
| IDdoProduto | Cor | Preço |
|---|
| 1 | marrom, amarelo | $15 |
| 2 | vermelho, verde | $13 |
| 3 | azul, laranja | $11 |
Você pode ficar tentado a contornar isso dividindo esses dados em colunas adicionais, mas isso também vai contra as regras: uma tabela com grupos de atributos repetidos ou intimamente relacionados não atende à primeira forma normal. A tabela abaixo, por exemplo, não está em conformidade:

Em vez disso, divida os dados em várias tabelas ou registros até que cada célula contenha apenas um valor e não haja colunas extras. Nesse ponto, diz-se que os dados são atômicos, ou divididos no menor tamanho útil. Para a tabela acima, você poderia criar uma tabela adicional chamada "Detalhes das vendas" que corresponderia a produtos específicos com vendas. "Vendas" teria então um relacionamento 1:M com "Detalhes das vendas".
Segunda forma normal
A segunda forma normal (2FN) exige que cada um dos atributos dependa totalmente de toda a chave primária. Isso significa que cada atributo deve depender diretamente da chave primária, e não indiretamente por meio de algum outro atributo.
Por exemplo, diz-se que um atributo "idade" que depende de "data de nascimento", que por sua vez depende de "IDdoAluno", tem uma dependência funcional parcial, e uma tabela contendo esses atributos deixaria de atender à segunda forma normal.
Além disso, uma tabela com uma chave primária composta por vários campos viola a segunda forma normal se um ou mais dos outros campos não dependerem de todas as partes da chave.
Assim, uma tabela com esses campos não atenderia à segunda forma normal, porque o atributo "nome do produto" depende do ID do produto, mas não do número do pedido:
Terceira forma normal
A terceira forma normal (3FN) adiciona a essas regras o requisito de que cada coluna que não seja chave seja independente de todas as outras colunas. Se a alteração de um valor em uma coluna que não seja chave fizer com que outro valor seja alterado, essa tabela não atenderá à terceira forma normal.
Isso evita que você armazene quaisquer dados derivados na tabela, como a coluna "imposto" abaixo, que depende diretamente do preço total do pedido:
| Pedido | Preço | Imposto |
| 14325 | $40.99 | $2.05 |
| 14326 | $13.73 | $.69 |
| 14327 | $24.15 | $1.21 |
Formas adicionais de normalização foram propostas, incluindo a forma normal de Boyce-Codd, da quarta à sexta formas normais e a forma normal de chave de domínio, mas as três primeiras são as mais comuns.
Embora essas formas expliquem as melhores práticas a serem seguidas de maneira geral, o grau de normalização depende do contexto do banco de dados.
Dados multidimensionais
Alguns usuários podem querer acessar várias dimensões de um único tipo de data, principalmente em bancos de dados OLAP. Por exemplo, eles podem querer saber as vendas por cliente, estado e mês. Nessa situação, é melhor criar uma tabela de fatos central à qual outras tabelas de clientes, estados e meses possam se referir, assim:

Regras de integridade de dados
Você também deve configurar seu banco de dados para validar os dados de acordo com as regras apropriadas. Muitos sistemas de gerenciamento de banco de dados, como o Microsoft Access, aplicam algumas dessas regras automaticamente.
A regra de integridade da entidade diz que a chave primária nunca pode ser NULL. Se a chave for composta por várias colunas, nenhuma delas poderá ser NULL. Caso contrário, ela poderá falhar em identificar exclusivamente o registro.
A regra de integridade referencial exige que cada chave estrangeira listada em uma tabela corresponda a uma chave primária na tabela que ela referencia. Se a chave primária for alterada ou excluída, essas alterações precisarão ser implementadas onde quer que essa chave seja referenciada em todo o banco de dados.
As regras de integridade da lógica de negócios garantem que os dados se ajustem a certos parâmetros lógicos. Por exemplo, o horário de um compromisso teria que cair dentro do horário comercial normal.
Adicionando índices e exibições
Um índice é essencialmente uma cópia classificada de uma ou mais colunas, com os valores em ordem crescente ou decrescente. A adição de um índice permite que os usuários encontrem registros mais rapidamente. Em vez de reclassificar para cada consulta, o sistema pode acessar os registros na ordem especificada pelo índice.
Embora os índices acelerem a recuperação de dados, eles podem desacelerar a inserção, atualização e exclusão, já que o índice precisa ser reconstruído sempre que um registro é alterado.
Uma exibição é simplesmente uma consulta salva nos dados. Elas podem unir dados de várias tabelas de forma útil ou mostrar parte de uma tabela.
Propriedades estendidas
Depois de concluir a estrutura básica, você poderá refinar o banco de dados com propriedades estendidas, como textos de instrução, máscaras de entrada e regras de formatação aplicadas a um esquema, visualização ou coluna específicos. A vantagem é que, como essas regras são armazenadas no próprio banco de dados, a apresentação dos dados será consistente nos vários programas que acessam os dados.
SQL e UML
A Linguagem de Modelagem Unificada (UML) é outra maneira visual de expressar sistemas complexos criados em uma linguagem orientada a objetos. Vários dos conceitos mencionados neste guia são conhecidos na UML por nomes diferentes. Por exemplo, uma entidade é conhecida como uma classe na UML.
A UML não é usada hoje com tanta frequência quanto no passado. Hoje, ela costuma ser usada academicamente e em comunicações entre designers de software e seus clientes.
Sistemas de gerenciamento de banco de dados
Muitas das escolhas de design que você fará dependem de qual sistema de gerenciamento de banco de dados você usa. Alguns dos sistemas mais comuns incluem:
-
Oracle DB
-
MySQL
-
Microsoft SQL Server
-
PostgreSQL
-
IBM DB2
Quando tiver a opção, escolha um sistema de gerenciamento de banco de dados apropriado com base no custo, nos sistemas operacionais, nos recursos e muito mais.
Esquema no sistema Oracle Database
No sistema de banco de dados Oracle, o termo esquema de banco de dados, também conhecido como "esquema SQL", tem um significado diferente. Aqui, um banco de dados pode ter vários esquemas (ou "schemata", se você quiser ser mais formal). Cada um contém todos os objetos criados por um usuário específico do banco de dados. Esses objetos podem incluir tabelas, exibições, sinônimos e muito mais. Alguns objetos não podem ser incluídos em um esquema, como usuários, contextos, funções e objetos de diretório.

Os usuários podem receber acesso para fazer login em esquemas individuais caso a caso, e a propriedade é transferível. Como cada objeto está associado a um esquema específico, que serve como uma espécie de namespace, é útil fornecer alguns sinônimos, o que permite que outros usuários acessem esse objeto sem primeiro se referirem ao esquema ao qual ele pertence.
Esses esquemas não indicam necessariamente a maneira como os arquivos de dados são armazenados fisicamente. Em vez disso, os objetos do esquema são armazenados logicamente dentro de um espaço de tabela. O administrador do banco de dados pode especificar quanto espaço atribuir a um objeto específico dentro de um arquivo de dados.
Por fim, os esquemas e os espaços de tabela não se alinham necessariamente perfeitamente: objetos de um esquema podem ser encontrados em vários espaços de tabela, enquanto um espaço de tabela pode incluir objetos de vários esquemas.
Instância de banco de dados ou esquema de banco de dados?
Esses termos, embora relacionados, não significam a mesma coisa. Um esquema de banco de dados é um esboço de um banco de dados planejado. Ele não contém dados de verdade.
Uma instância de banco de dados, por outro lado, é um instantâneo de um banco de dados como ele existia em um determinado momento. Assim, as instâncias de banco de dados podem mudar com o tempo, enquanto um esquema de banco de dados geralmente é estático, já que é difícil alterar a estrutura de um banco de dados quando ele já está operacional.
Os esquemas de banco de dados e as instâncias de banco de dados podem afetar uns aos outros por meio de um sistema de gerenciamento de banco de dados (SGBD). O SGBD garante que cada instância de banco de dados esteja em conformidade com as restrições impostas pelos designers de banco de dados no esquema de banco de dados.
Requisitos de integração de esquemas
Pode ser útil integrar várias fontes em um único esquema. Certifique-se de que estes requisitos sejam atendidos para uma transição perfeita:
Preservação de sobreposição
Cada elemento sobreposto nos esquemas que você está integrando deve estar em uma tabela de esquema de banco de dados.
Preservação de sobreposição estendida
Elementos que aparecem apenas em uma fonte, mas que estão associados a elementos sobrepostos, devem ser copiados para o esquema de banco de dados resultante.
Normalização
Relacionamentos e entidades independentes não devem ser agrupados na mesma tabela no esquema do banco de dados.
Minimalidade
O ideal é que nenhum dos elementos de nenhuma das fontes seja perdido.
Tipos de esquema de banco de dados
Certos padrões se desenvolveram no design de esquemas de banco de dados.
O esquema estrela, amplamente utilizado, também é o mais simples. Nele, uma ou mais tabelas de fatos são vinculadas a qualquer número de tabelas dimensionais. É ideal para lidar com consultas simples.
O esquema floco de neve relacionado também é usado para representar um banco de dados multidimensional. Nesse padrão, no entanto, as dimensões são normalizadas em várias tabelas separadas, criando o efeito expansivo de uma estrutura semelhante a um floco de neve.