Anforderungsanalyse: Den Zweck der Datenbank präzise bestimmen
Das tiefgreifende Verständnis des genauen Zwecks Ihrer Datenbank wird all Ihre Entscheidungen während des gesamten Designprozesses maßgeblich beeinflussen. Stellen Sie sicher, dass Sie die Datenbank aus jeder denkbaren Perspektive beleuchten. Würden Sie beispielsweise eine Datenbank für eine öffentliche Bibliothek erstellen, müssten Sie zwingend die spezifischen Wege berücksichtigen, auf denen sowohl Bibliotheksnutzende als auch das Personal auf die Daten zugreifen müssen.
Hier sind bewährte Methoden, um vor der eigentlichen Erstellung der Datenbank relevante Informationen zu sammeln:
- Führen Sie strukturierte Interviews mit den Personen, die das System künftig nutzen werden.
- Analysieren Sie bestehende Geschäftsdokumente wie Rechnungen, Stundenzettel oder Fragebögen.
- Sichten Sie alle bereits vorhandenen Datensysteme (einschließlich physischer Akten und digitaler Dateien).
Beginnen Sie damit, sämtliche bestehenden Daten zusammenzutragen, die in die Datenbank einfließen sollen. Erstellen Sie im Anschluss eine Liste der zu speichernden Datentypen sowie der Entitäten – also Personen, Objekte, Standorte und Ereignisse –, die durch jene Daten beschrieben werden, wie im Folgenden dargestellt:
Kund:innen
- Name
- Adresse
- Ort, Bundesland, Postleitzahl
- E-Mail-Adresse
Produkte
- Name
- Preis
- Lagerbestand
- Bestellte Menge
Bestellungen
- Bestell-ID
- Vertriebsmitarbeitende
- Datum
- Produkt(e)
- Menge
- Preis
- Gesamtsumme
Diese Informationen bilden später das Fundament für das Data Dictionary, welches die Tabellen und Felder innerhalb der Datenbank detailliert umreißt. Achten Sie unbedingt darauf, die Informationen in die kleinstmöglichen, sinnvollen Einheiten zu zerlegen. Es empfiehlt sich beispielsweise, die Straße vom Land zu trennen, um Personen später problemlos nach ihrem Wohnsitzland filtern zu können. Vermeiden Sie es zudem konsequent, denselben Datenpunkt in mehr als einer Tabelle zu hinterlegen, da dies zu unnötiger Komplexität führt.
Sobald Klarheit darüber herrscht, welche Datenarten die Datenbank umfassen soll, woher diese stammen und wie sie genutzt werden, können Sie mit der konkreten Planung der eigentlichen Datenbank beginnen.
Datenbankstruktur: Die grundlegenden Bausteine einer Datenbank
Der nächste logische Schritt besteht darin, eine visuelle Darstellung Ihrer Datenbank auszuarbeiten. Um dies erfolgreich umzusetzen, müssen Sie präzise verstehen, wie relationale Datenbanken strukturiert sind.
Innerhalb einer Datenbank werden zusammengehörige Daten in Tabellen gruppiert, von denen jede – ähnlich wie eine Tabellenkalkulation – aus Zeilen (auch Tupel genannt) und Spalten besteht.
Um Ihre gesammelten Datenlisten in Tabellen zu überführen, erstellen Sie zunächst für jeden Entitätstyp (wie Produkte, Verkäufe, Kund:innen und Bestellungen) eine eigene Tabelle. Hier ist ein anschauliches Beispiel:
Jede Zeile einer Tabelle wird als Datensatz bezeichnet. Datensätze enthalten spezifische Informationen über ein bestimmtes Objekt oder eine Person, wie etwa zu einem konkreten Kunden. Im Gegensatz dazu umfassen Spalten (auch als Felder oder Attribute bekannt) jeweils eine einzige Informationsart, die in jedem Datensatz auftaucht – wie beispielsweise die Postleitzahlen aller in der Tabelle geführten Kund:innen.
| Vorname | Nachname | Alter | Postleitzahl |
|---|
| Roger | Williams | 43 | 34760 |
| Jerrica | Jorgensen | 32 | 97453 |
| Samantha | Hopkins | 56 | 64829 |
Um eine durchgängige Datenkonsistenz von einem Datensatz zum nächsten zu gewährleisten, weisen Sie jeder Spalte den passenden Datentyp zu. Zu den am häufigsten verwendeten Datentypen gehören:
- CHAR – Text mit einer fest definierten Länge
- VARCHAR – Text mit variabler Länge
- TEXT – Für sehr große Textmengen
- INT – Positive oder negative ganze Zahlen
- FLOAT, DOUBLE – Zur Speicherung von Gleitkommazahlen
- BLOB – Für Binärdaten
Einige Datenbankmanagementsysteme bieten darüber hinaus den Datentyp „Autonummer“ an, welcher in jeder Zeile automatisch eine unverkennbare, fortlaufende Nummer generiert.
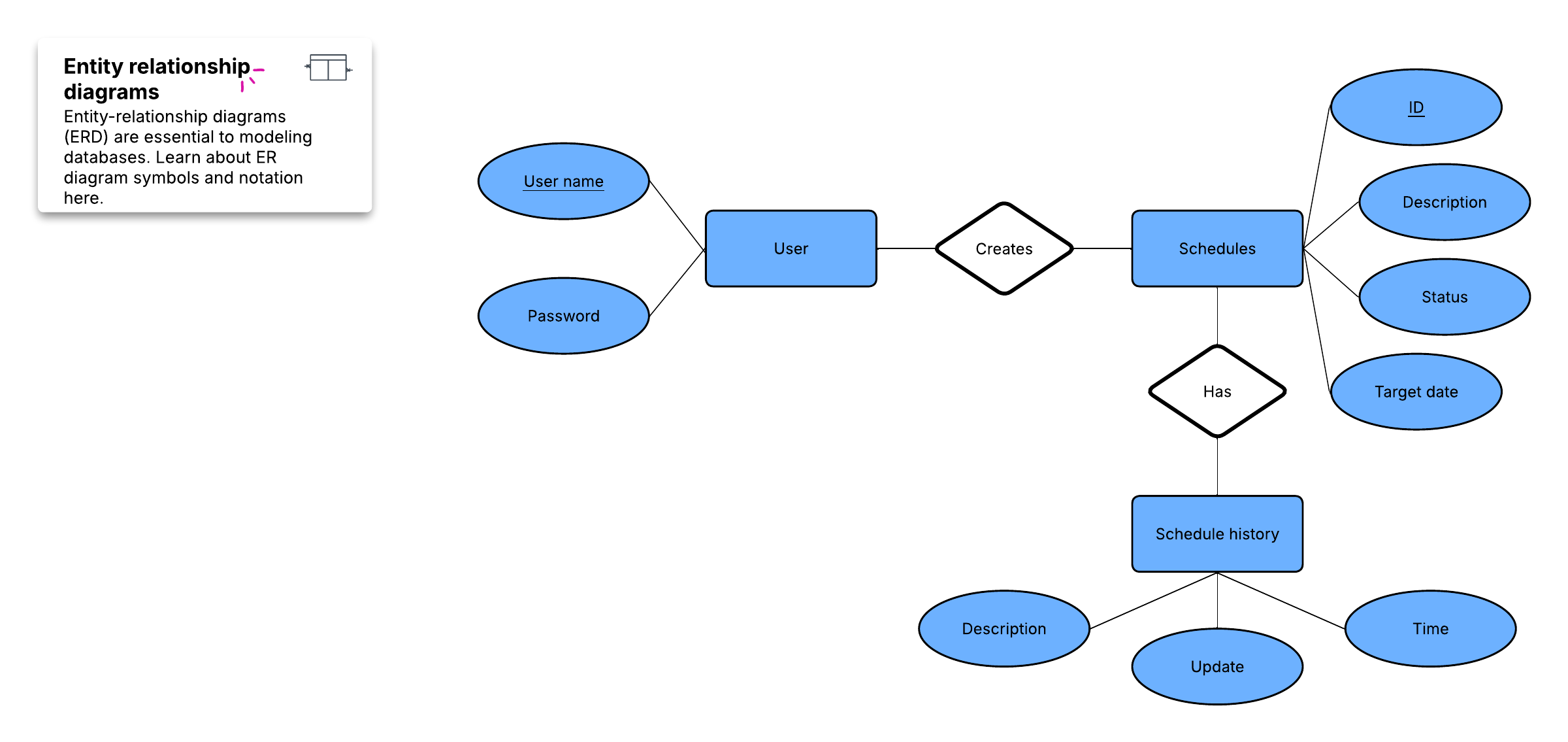
Für die Erstellung einer visuellen Übersicht der Datenbank, dem sogenannten Entity-Relationship-Diagramm, bilden Sie nicht die realen Tabellen ab. Stattdessen wird jede Tabelle als Kasten im Diagramm dargestellt. Der Titel des Kastens benennt das Thema der Tabellendaten, während die zugehörigen Attribute darunter aufgelistet werden:

Abschließend müssen Sie festlegen, welches Attribut oder welche Kombination von Attributen als Primärschlüssel für die jeweilige Tabelle dienen soll. Ein Primärschlüssel (PK) fungiert als eindeutiger Identifikator für eine bestimmte Entität, sodass Sie einen exakten Datensatz selbst dann fehlerfrei bestimmen können, wenn Ihnen nur dieser eine Wert vorliegt.
Als Primärschlüssel ausgewählte Attribute müssen zwingend eindeutig sowie unveränderlich sein und in jedem Datensatz existieren (sie dürfen niemals NULL oder leer sein). Aus diesem Grund eignen sich Bestellnummern oder Benutzernamen hervorragend als Primärschlüssel, während Telefonnummern oder Straßenbezeichnungen ungeeignet sind. Sie können zudem mehrere Felder kombiniert als Primärschlüssel definieren (dies wird als zusammengesetzter Schlüssel bezeichnet).
Sobald die reale Datenbank implementiert wird, übertragen Sie sowohl die logische als auch die physische Datenstruktur in die Datendefinitionssprache Ihres gewählten Datenbankmanagementsystems. Zu diesem Zeitpunkt sollten Sie auch eine fundierte Schätzung der künftigen Datenbankgröße vornehmen, um sicherzustellen, dass das System das erforderliche Leistungsniveau und den notwendigen Speicherplatz bietet.
Beziehungen zwischen Entitäten definieren
Da Ihre Datenstrukturen nun in Tabellenform vorliegen, können Sie mit der präzisen Analyse der Beziehungen zwischen den einzelnen Tabellen beginnen. Die Kardinalität beschreibt dabei die quantitative Anzahl der Elemente, die zwischen zwei miteinander verknüpften Tabellen interagieren. Das korrekte Identifizieren der Kardinalität stellt sicher, dass Sie Ihre Daten auf die effizienteste Art und Weise auf die Tabellen aufgeteilt haben.
Jede Entität kann potenziell mit jeder anderen in Beziehung stehen, wobei sich diese Verbindungen typischerweise in drei Kategorien einteilen lassen:
Eins-zu-eins-Beziehungen
Wenn für jede Instanz der Entität A exakt eine Instanz der Entität B existiert, spricht man von einer Eins-zu-eins-Beziehung (oft als 1:1 geschrieben). In einem ER-Diagramm lässt sich diese Beziehungsart durch eine einfache Linie visualisieren, die an beiden Enden mit einem Querstrich versehen ist:

Sofern keine gewichtigen Gründe dagegen sprechen, deutet eine 1:1-Beziehung meist darauf hin, dass es sinnvoller wäre, die Daten der beiden separaten Tabellen in einer einzigen Tabelle zusammenzufassen.
Es gibt jedoch spezifische Szenarien, in denen Tabellen mit einer 1:1-Beziehung absolut vorteilhaft sind. Falls Sie ein Feld mit optionalen Daten führen – wie etwa eine ausführliche „Beschreibung“, die bei vielen Datensätzen leer bleibt –, können Sie all diese Beschreibungen in eine eigene Tabelle auslagern. Dadurch eliminieren Sie ungenutzten Speicherplatz und steigern die Gesamtperformance der Datenbank.
Um die korrekte Zuordnung der Daten zu garantieren, müssen Sie in diesem Fall in beiden Tabellen mindestens eine identische Spalte einfügen, worafür sich primär der Primärschlüssel anbietet.
Eins-zu-viele-Beziehungen
Diese Verknüpfungen treten auf, wenn ein einzelner Datensatz in einer Tabelle mit mehreren Einträgen in einer anderen Tabelle assoziiert ist. Beispielsweise kann ein einzelner Kunde viele verschiedene Bestellungen aufgeben oder eine Person im der Bibliothek mehrere Bücher gleichzeitig entliehen haben. Eins-zu-viele-Beziehungen (1:N) werden in Diagrammen über die sogenannte „Krähenfuß-Notation“ dargestellt, wie dieses Beispiel verdeutlicht:

Um eine 1:N-Beziehung beim Einrichten einer Datenbank praktisch umzusetzen, fügen Sie einfach den Primärschlüssel der „Eins“-Seite als Attribut in die Tabelle der „Viele“-Seite ein. Wird ein Primärschlüssel auf diese Weise in einer anderen Tabelle aufgeführt, bezeichnet man ihn als Fremdschlüssel. Die Tabelle auf der „1“-Seite der Beziehung fungiert hierbei als übergeordnete Tabelle (Parent Table) für die untergeordnete Tabelle (Child Table) auf der gegenüberliegenden Seite.
Viele-zu-viele-Beziehungen
Können mehrere Entitäten einer Tabelle mit mehreren Entitäten einer anderen Tabelle verknüpft sein, liegt eine Viele-zu-viele-Beziehung (M:N) vor. Ein klassisches Beispiel hierfür ist das Verhältnis zwischen Studierenden und Kursen, da eine studierende Person viele Kurse belegen kann und ein Kurs gleichzeitig viele Studierende umfasst.
In einem ER-Diagramm werden diese komplexen Beziehungen mit folgenden Linien dargestellt:

Unglücklicherweise ist es technisch nicht direkt möglich, diese Beziehungsart unverändert in einer relationalen Datenbank abzubilden. Stattdessen müssen Sie diese zwingend in zwei separate Eins-zu-viele-Beziehungen aufbrechen.
Erstellen Sie dazu eine neue Verknüpfungsentität zwischen den beiden ursprünglichen Tabellen. Existiert die M:N-Beziehung etwa zwischen Verkäufen und Produkten, könnten Sie diese neue Entität „verkaufte_produkte“ nennen, da sie den genauen Inhalt jedes Verkaufs abbildet. Sowohl die Verkaufs- als auch die Produkttabelle weisen dann jeweils eine 1:N-Beziehung zur Tabelle „verkaufte_produkte“ auf. Eine solche vermittelnde Entität wird je nach Modell als Kopplungstabelle, assoziative Entität oder Zwischentabelle bezeichnet.
Jeder Datensatz in dieser Zwischentabelle führt zwei Entitäten der angrenzenden Tabellen zusammen und kann bei Bedarf zusätzliche Zusatzinformationen enthalten. Eine Zwischentabelle zwischen Studierenden und Kursen könnte beispielsweise folgendes Aussehen haben:

Optional oder obligatorisch?
Ein weiterer wichtiger Aspekt bei der Analyse von Beziehungen ist die Frage, welche Seite der Verbindung zwingend existieren muss, damit die andere existieren kann. Die optionale, also nicht obligatorische Seite wird im Diagramm mit einem kleinen Kreis auf der Linie markiert, wo sich sonst ein Querstrich befindet. So muss beispielsweise ein Land zwingend existieren, damit es eine Vertretung in den Vereinten Nationen stellen kann, wohingegen der umgekehrte Fall nicht zwingend gegeben ist:

Ebenso können zwei Entitäten wechselseitig voneinander abhängig sein, sodass die eine ohne die andere überhaupt nicht existieren könnte.
Rekursive Beziehungen
In bestimmten Fällen verweist eine Tabelle auf sich selbst zurück. Wenn eine Tabelle mit Mitarbeitenden beispielsweise ein Attribut „Vorgesetzter“ enthält, welches sich wiederum auf eine andere Person in exakt derselben Tabelle bezieht, spricht man von einer rekursiven Beziehung.
Redundante Beziehungen
Eine redundante Beziehung liegt vor, wenn eine Verknüpfung mehr als einmal im System ausgedrückt wird. In der Regel können Sie eine dieser Beziehungen entfernen, ohne dass dabei relevante Informationen verloren gehen. Besitzt beispielsweise die Entität „Studierende“ eine direkte Beziehung zur Entität „Lehrkräfte“, ist aber gleichzeitig indirekt über die Entität „Kurse“ mit den Lehrkräften verknüpft, sollten Sie die direkte Verbindung kappen. Es ist ratsam, jene direkte Beziehung zu löschen, da die Zuordnung von Studierenden zu Lehrkräften ausschließlich über die belegten Kurse erfolgt.
Datenbank-Normalisierung
Sobald Ihnen ein vorläufiger Entwurf Ihrer Datenbank vorliegt, können Sie Normalisierungsregeln anwenden, um sicherzustellen, dass die Tabellen absolut korrekt strukturiert sind. Betrachten Sie diese Regeln einfach als die etablierten Industriestandards.
Gleichwohl eignen sich keineswegs alle Datenbanken uneingeschränkt für eine vollständige Normalisierung. Generell sollten OLTP-Datenbanken (Online Transaction Processing), bei denen der Fokus der Nutzenden auf dem Erstellen, Lesen, Aktualisieren und Löschen von Datensätzen liegt, konsequent normalisiert werden.
OLAP-Datenbanken (Online Analytical Processing), die primär für Analysen und das Berichtswesen optimiert sind, fahren hingegen oft mit einem gewissen Grad an Denormalisierung besser, da hier die reine Rechengeschwindigkeit im Vordergrund steht. Hierzu zählen beispielsweise Anwendungen zur Entscheidungsunterstützung, bei denen Daten extrem schnell analysiert, jedoch nicht modifiziert werden müssen.
Jede Normalform beziehungsweise Normalisierungsstufe schließt die Bedingungen der jeweils untergeordneten Stufen vollständig ein.
Erste Normalform
Die erste Normalform (abgekürzt als 1NF) schreibt zwingend vor, dass jede einzelne Zelle einer Tabelle nur einen einzigen Wert und niemals eine Liste von Werten enthalten darf. Eine Tabelle wie die folgende verstößt somit gegen diese Regel:
| ProduktID | Farbe | Preis |
|---|
| 1 | braun, gelb | $15 |
| 2 | rot, grün | $13 |
| 3 | blau, orange | $11 |
Man könnte nun versucht sein, diese Regel zu umgehen, indem man die Daten einfach auf zusätzliche Spalten aufteilt, doch auch dies ist unzulässig: Eine Tabelle mit Gruppen wiederkehrender oder eng miteinander verwandter Attribute erfüllt die Kriterien der ersten Normalform nicht. Die unten stehende Tabelle verletzt diese Vorgabe beispielsweise deutlich:

Spalten Sie die Daten stattdessen so lange auf mehrere Tabellen oder Datensätze auf, bis jede Zelle nur noch einen einzigen Wert enthält und keine überflüssigen Spalten mehr existieren. Sobald dieser Zustand erreicht ist, werden die Daten als atomar bezeichnet – sie sind auf die kleinstmögliche, sinnvolle Einheit reduziert. Für das obige Beispiel könnten Sie eine zusätzliche Tabelle namens „Verkaufsdetails“ erstellen, die spezifische Produkte mit Verkäufen verknüpft. „Verkäufe“ stünde dann in einer 1:N-Beziehung zu den „Verkaufsdetails“.
Zweite Normalform
Die zweite Normalform (2NF) setzt voraus, dass jedes Nicht-Schlüssel-Attribut voll funktionell vom gesamten Primärschlüssel abhängig sein muss. Das bedeutet konkret, dass jedes Attribut direkt vom Primärschlüssel abhängen muss und nicht indirekt über ein anderes Attribut transportiert werden darf.
Hängt beispielsweise ein Attribut „Alter“ vom Attribut „Geburtsdatum“ ab, welches wiederum vom „StudierendenID“ abhängt, liegt eine partielle funktionelle Abhängigkeit vor. Eine solche Tabelle würde die Kriterien der zweiten Normalform folglich nicht erfüllen.
Darüber hinaus verletzt eine Tabelle mit einem aus mehreren Feldern zusammengesetzten Primärschlüssel die zweite Normalform, sofern ein oder mehrere der übrigen Felder nicht von sämtlichen Teilen des Schlüssels abhängig sind.
Demnach würde eine Tabelle mit den folgenden Feldern der zweiten Normalform widersprechen, da das Attribut „Produktname“ zwar von der Produkt-ID, nicht aber von der Bestellnummer abhängt:
Dritte Normalform
Die dritte Normalform (3NF) erweitert diese Anforderungen um die Bedingung, dass jedes Nicht-Schlüssel-Kolumnenelement von jedem anderen Kolumnenelement vollkommen unabhängig sein muss. Führt das Ändern eines Wertes in einer Nicht-Schlüssel-Spalte unweigerlich dazu, dass sich ein Wert in einer anderen Spalte ändert, erfüllt jene Tabelle die dritte Normalform nicht.
Dies unterbindet effektiv das Speichern jeglicher abgeleiteter Daten in der Tabelle, wie es bei der unten aufgeführten Spalte „Steuer“ der Fall ist, da diese direkt vom Gesamtwert der Bestellung abhängt:
| Bestellung | Preis | Steuer |
| 14325 | $40.99 | $2.05 |
| 14326 | $13.73 | $.69 |
| 14327 | $24.15 | $1.21 |
Es wurden zwar noch weitere Normalformen vorgeschlagen – wie die Boyce-Codd-Normalform sowie die vierte bis sechste Normalform und die Domänen-Schlüssel-Normalform –, in der alltäglichen Praxis sind jedoch die ersten drei Formen am weitesten verbreitet.
Obwohl diese Formen allgemein die besten Praktiken definieren, hängt das exakte Maß der Normalisierung immer vom spezifischen Kontext und Einsatzzweck der jeweiligen Datenbank ab.
Multidimensionale Daten
Bestimmte Anwendende müssen auf mehrere Dimensionen eines einzelnen Datentyps zugreifen, was insbesondere bei OLAP-Datenbanken der Fall ist. Sie möchten beispielsweise die Umsätze aufgeschlüsselt nach Kund:innen, Bundesländern und Monaten einsehen. In einem solchen Szenario empfiehlt es sich, eine zentrale Faktentabelle anzulegen, auf welche die übrigen Tabellen für Kund:innen, Bundesländer und Monate verweisen können:

Regeln zur Datenintegrität
Sie sollten Ihre Datenbank zudem so konfigurieren, dass sie sämtliche Daten auf Basis definierter Regeln validiert. Viele moderne Datenbankmanagementsysteme, wie etwa Microsoft Access, erzwingen einen Teil dieser Integritätsbedingungen vollautomatisch.
Die Regel zur Entitätsintegrität besagt unmissverständlich, dass ein Primärschlüssel niemals den Wert NULL annehmen darf. Setzt sich der Schlüssel aus mehreren Spalten zusammen, darf folglich keine einzige davon NULL sein, da andernfalls eine eindeutige Identifizierung des Datensatzes fehlschlägt.
Die Regel zur referenziellen Integrität verlangt, dass jeder in einer Tabelle aufgeführte Fremdschlüssel exakt einem existierenden Primärschlüssel in der referenzierten Tabelle entsprechen muss. Ändert sich der Primärschlüssel oder wird dieser gelöscht, müssen jene Modifikationen zwingend an allen Stellen nachgezogen werden, an denen der Schlüssel innerhalb der Datenbank referenziert wird.
Integritätsregeln für die Geschäftslogik stellen sicher, dass alle Daten innerhalb logisch definierter Parameter liegen. So muss ein vereinbarter Termin beispielsweise zwingend in die regulären Geschäftszeiten fallen.
Indizes und Ansichten hinzufügen
Ein Index stellt im Grunde eine sortierte Kopie einer oder mehrerer Spalten dar, deren Werte entweder in auf- oder absteigender Reihenfolge vorliegen. Das Hinzufügen eines Index ermöglicht es Nutzenden, Datensätze erheblich schneller zu finden. Anstatt bei jeder Abfrage eine vollständige Neusortierung durchzuführen, greift das System direkt in der durch den Index vorgegebenen Reihenfolge auf die Datensätze zu.
Obwohl Indizes das Abrufen von Daten spürbar beschleunigen, können sie das Einfügen, Aktualisieren und Löschen verlangsamen, da der Index bei jeder Änderung eines Datensatzes neu aufgebaut werden muss.
Eine Ansicht (View) ist vereinfacht gesagt eine gespeicherte Abfrage auf den Datenbeständen. Ansichten eignen sich hervorragend dazu, Daten aus mehreren Tabellen zusammenzuführen oder lediglich einen spezifischen Teilbereich einer Tabelle abzubilden.
Erweiterte Eigenschaften
Sobald das grundlegende Layout steht, können Sie die Datenbank durch erweiterte Eigenschaften verfeinern, wie etwa durch Anleitungstexte, Eingabemasken und Formatierungsregeln, die für ein bestimmtes Schema, eine Ansicht oder eine Spalte gelten. Der große Vorteil liegt darin, dass diese Regeln direkt in der Datenbank hinterlegt sind, wodurch die Datendarstellung über alle zugreifenden Programme hinweg vollkommen konsistent bleibt.
SQL und UML
Die Unified Modeling Language (UML) stellt eine weitere visuelle Methode dar, um komplexe Systeme auszudrücken, die in einer objektorientierten Sprache entwickelt wurden. Einige der in diesem Leitfaden erwähnten Konzepte sind in UML unter anderen Bezeichnungen bekannt. So wird eine Entität in UML beispielsweise als Klasse bezeichnet.
UML wird in der heutigen Praxis nicht mehr so häufig eingesetzt wie in der Vergangenheit. Heutzutage findet sie vorwiegend im akademischen Bereich sowie bei der Kommunikation zwischen Softwaredesigner:innen und deren Kundschaft Verwendung.
Datenbankmanagementsysteme
Viele Ihrer Designentscheidungen hängen stark davon ab, welches konkrete Datenbankmanagementsystem Sie einsetzen. Zu den am weitesten verbreiteten Systemen gehören:
-
Oracle DB
-
MySQL
-
Microsoft SQL Server
-
PostgreSQL
-
IBM DB2
Wählen Sie das für Sie am besten geeignete Datenbankmanagementsystem sorgfältig auf Basis von Faktoren wie Kosten, Betriebssystemen, Funktionsumfang und weiteren individuellen Anforderungen aus.
Schemata im Oracle-Datenbanksystem
Im Oracle-Datenbanksystem hat der Begriff Datenbankschema, welcher auch als „SQL-Schema“ bezeichnet wird, eine abweichende Bedeutung. Hier kann eine einzige Datenbank mehrere Schemata umfassen. Jedes einzelne davon enthält sämtliche Objekte, die von einem ganz bestimmten Datenbanknutzenden erstellt wurden. Jene Objekte können Tabellen, Ansichten, Synonyme und vieles mehr umfassen. Einige Objekte lassen sich jedoch nicht in ein Schema integrieren, wie etwa Nutzende, Kontexte, Rollen und Verzeichnisobjekte.

Nutzenden kann der Zugriff für die Anmeldung an einzelnen Schemata von Fall zu Fall gewährt werden, und die Inhaberschaft ist problemlos übertragbar. Da jedes Objekt mit einem bestimmten Schema verknüpft ist, das als eine Art Namensraum fungiert, ist es ratsam, Synonyme zu vergeben. Dies erlaubt es anderen Nutzenden, auf ein Objekt zuzugreifen, ohne vorher das zugehörige Schema explizit referenzieren zu müssen.
Diese Schemata spiegeln nicht zwingend die Art und Weise wider, wie die Datendateien physisch auf dem Datenträger gespeichert sind. Stattdessen werden Schemaobjekte logisch innerhalb eines Tablespaces abgelegt. Die datenbankadministrierende Person kann genau festlegen, wie viel Speicherplatz einem bestimmten Objekt innerhalb einer Datendatei zugewiesen wird.
Schließlich müssen Schemata und Tablespaces keineswegs vollkommen deckungsgleich sein: Objekte aus einem einzigen Schema können über mehrere Tablespaces hinweg verteilt sein, während ein Tablespace gleichzeitig Objekte aus verschiedenen Schemata beinhalten kann.
Datenbankinstanz oder Datenbankschema?
Diese beiden Begriffe sind zwar eng miteinander verwoben, bedeuten jedoch keineswegs dasselbe. Ein Datenbankschema ist der theoretische Entwurf einer geplanten Datenbank und enthält selbst noch keinerlei Realdaten.
Eine Datenbank-Instanz hingegen stellt eine exakte Momentaufnahme einer Datenbank zu einem ganz bestimmten Zeitpunkt dar. Folglich verändern sich Datenbank-Instanzen im Laufe der Zeit kontinuierlich, während ein Datenbankschema in der Regel statisch bleibt, da strukturelle Änderungen an einer bereits produktiven Datenbank mit erheblichem Aufwand verbunden sind.
Datenbankschemata und Datenbank-Instanzen beeinflussen sich gegenseitig über das Datenbankmanagementsystem (DBMS). Das DBMS stellt dabei permanent sicher, dass jede einzelne Datenbank-Instanz sämtliche im Datenbankschema definierten Einschränkungen strikt einhält.
Anforderungen an die Integration von Schemata
Es kann sich als äußerst nützlich erweisen, mehrere Datenquellen in einem einzigen Schema zusammenzuführen. Um einen reibungslosen Übergang zu gewährleisten, müssen die folgenden Anforderungen zwingend erfüllt sein:
Erhaltung von Überschneidungen
Jedes sich überschneidende Element in den zu integrierenden Schemata muss zwingend in einer Tabelle des resultierenden Datenbankschemas abgebildet sein.
Erweiterte Erhaltung von Überschneidungen
Elemente, die lediglich in einer einzigen Quelle auftauchen, jedoch mit sich überschneidenden Elementen assoziiert sind, müssen zwingend in das resultierende Datenbankschema übernommen werden.
Normalisierung
Unabhängige Beziehungen und Entitäten dürfen keinesfalls in derselben Tabelle des Datenbankschemas zusammengefasst werden.
Minimalität
Im Idealfall geht kein einziges Element aus den ursprünglichen Datenquellen während des Integrationsprozesses verloren.
Arten von Datenbankschemata
Im Bereich des Datenbank-Designs haben sich im Laufe der Zeit bewährte Strukturmuster etabliert.
Das weithin genutzte Star-Schema (Sternschema) stellt hierbei die einfachste Struktur dar. Bei diesem Muster werden eine oder mehrere Faktentabellen mit einer beliebigen Anzahl von Dimensionstabellen verknüpft. Es eignet sich hervorragend für das effiziente Handling einfacher Abfragen.
Das eng verwandte Snowflake-Schema (Schneeflockenschema) wird ebenfalls zur Darstellung multidimensionaler Datenbanken herangezogen. Bei diesem Muster werden die Dimensionen jedoch tiefergehend in zahlreiche separate Tabellen normalisiert, wodurch die namensgebende, weit verzweigte Struktur einer Schneeflocke entsteht.