Анализ требований: определение целей базы данных
Понимание назначения базы данных определит ваши решения на протяжении всего процесса проектирования. Обязательно рассмотрите базу данных со всех точек зрения. Например, если бы вы создавали базу данных для публичной библиотеки, вам нужно было бы учесть, как к данным будут обращаться как читатели, так и библиотекари.
Вот несколько способов сбора информации перед созданием базы данных:
- Опросите людей, которые будут ею пользоваться
- Проанализируйте бизнес-формы, такие как счета-фактуры, табели учета рабочего времени, опросы
- Изучите любые существующие системы данных (включая физические и цифровые файлы)
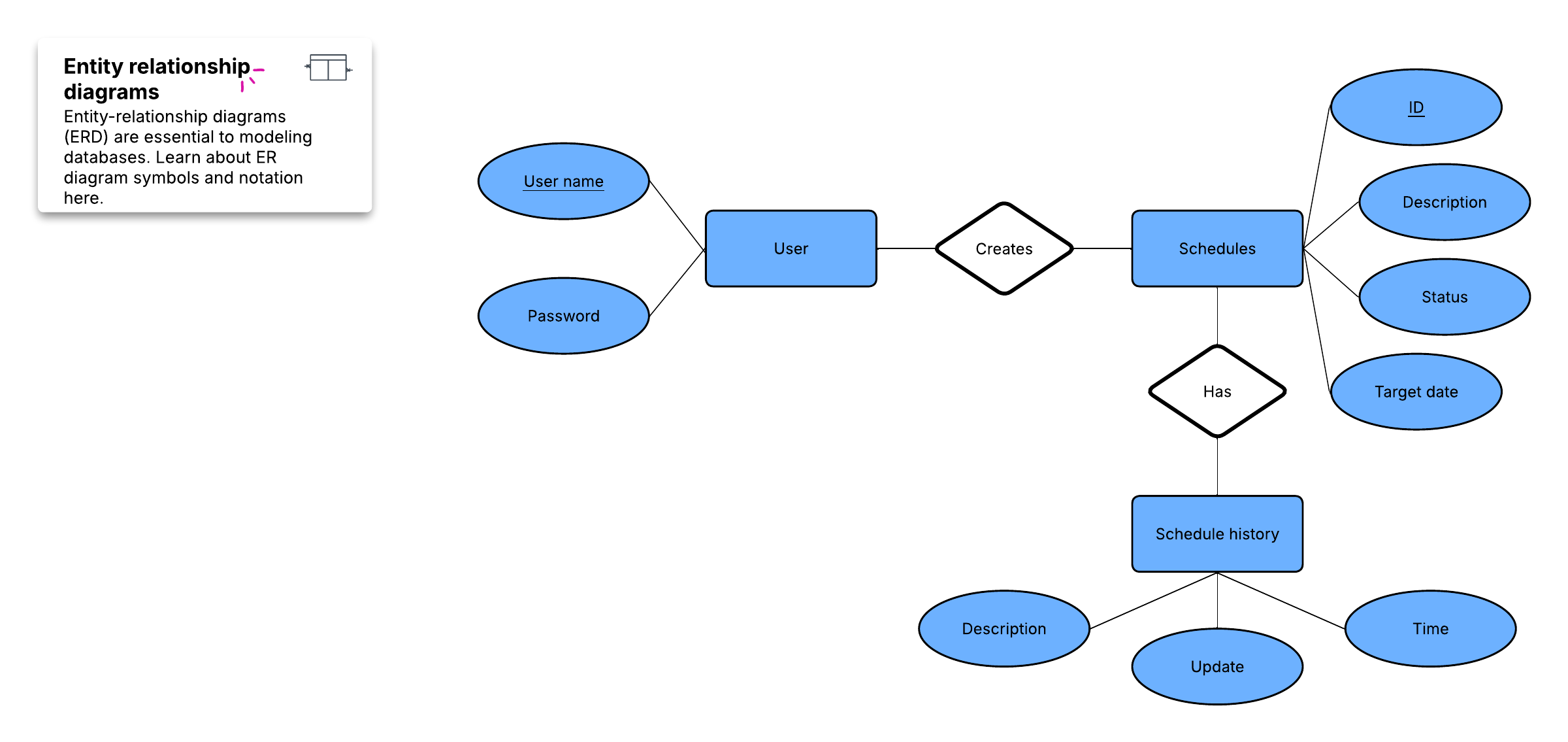
Начните со сбора всех существующих данных, которые будут включены в базу данных. Затем составьте список типов данных, которые вы хотите хранить, и сущностей — людей, предметов, мест и событий, которые эти данные описывают, например:
Клиенты
- Имя
- Адрес
- Город, область, почтовый индекс
- Адрес электронной почты
Товары
- Название
- Цена
- Количество на складе
- Количество в заказе
Заказы
- ID заказа
- Торговый представитель
- Дата
- Товар(ы)
- Количество
- Цена
- Итого
Эта информация позже станет частью словаря данных, который определяет таблицы и поля внутри базы данных. Обязательно разбивайте информацию на минимально возможные полезные элементы. Например, стоит отделить адрес (улицу и дом) от страны, чтобы позже можно было фильтровать людей по стране проживания. Также избегайте дублирования одних и тех же данных в нескольких таблицах, так как это неоправданно усложняет структуру.
Как только вы поймете, какие типы данных будут содержаться в базе, откуда они берутся и как будут использоваться, можно переходить к планированию самой базы данных.
Структура базы данных: основные строительные блоки
Следующий шаг — создание визуального представления базы данных. Для этого необходимо точно понимать, как устроены реляционные базы данных.
Внутри базы данных связанные данные группируются в таблицы, каждая из которых состоит из строк (также называемых кортежами) и столбцов, подобно электронной таблице.
Чтобы преобразовать списки данных в таблицы, начните с создания таблицы для каждого типа сущностей, таких как товары, продажи, клиенты и заказы. Вот пример:
Каждая строка таблицы называется записью. Записи содержат данные о ком-то или чем-то, например о конкретном клиенте. Напротив, столбцы (также называемые полями или атрибутами) содержат один тип информации, который присутствует в каждой записи, например адреса всех клиентов, перечисленных в таблице.
| Имя | Фамилия | Возраст | Почтовый индекс |
|---|
| Роджер | Уильямс | 43 | 34760 |
| Джеррика | Йоргенсен | 32 | 97453 |
| Саманта | Хопкинс | 56 | 64829 |
Чтобы обеспечить согласованность данных от одной записи к другой, назначьте каждому столбцу соответствующий тип данных. Общие типы данных включают:
- CHAR — текст фиксированной длины
- VARCHAR — текст переменной длины
- TEXT — большие объемы текста
- INT — положительное или отрицательное целое число
- FLOAT, DOUBLE — числа с плавающей запятой
- BLOB — двоичные данные
Некоторые системы управления базами данных также предлагают тип данных «Автонумерация», который автоматически генерирует уникальное число в каждой строке.
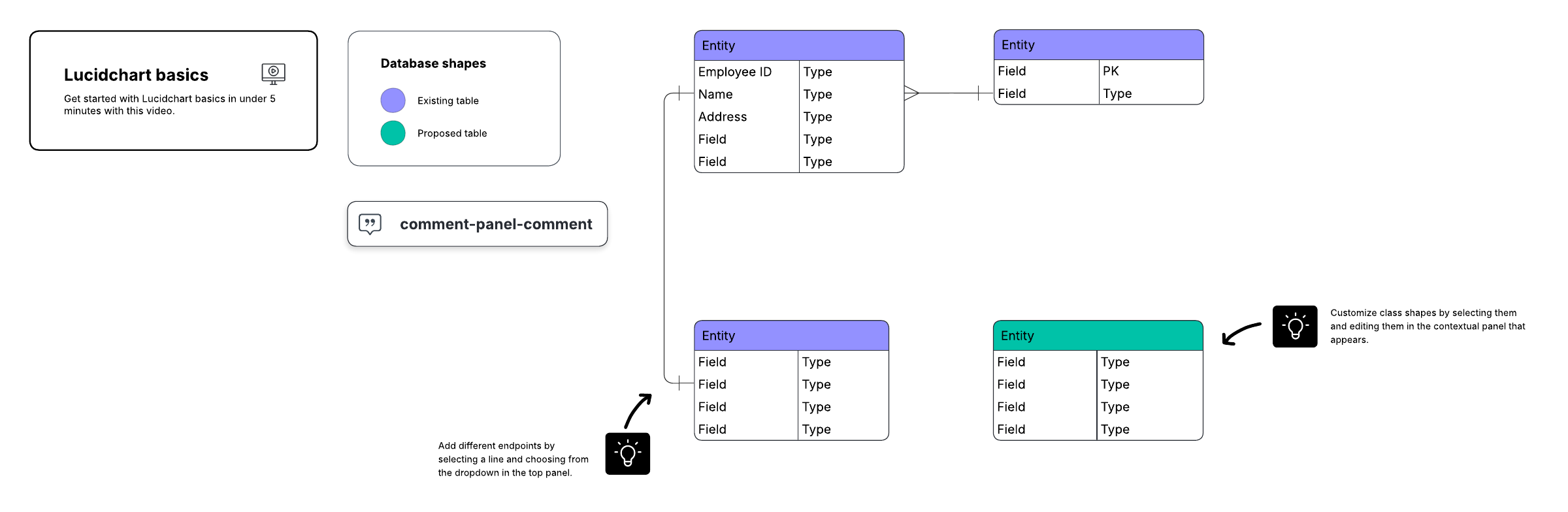
При создании визуального обзора базы данных, известного как ER-диаграмма (сущность-связь), сами таблицы не заполняются данными. Вместо этого каждая таблица становится блоком на диаграмме. Название каждого блока должно указывать, какие данные описывает эта таблица, а атрибуты перечисляются ниже, например:

Наконец, необходимо решить, какой атрибут или атрибуты будут служить первичным ключом для каждой таблицы (если применимо). Первичный ключ (PK) — это уникальный идентификатор для данной сущности, позволяющий безошибочно определить конкретного клиента, зная только это значение.
Атрибуты, выбранные в качестве первичных ключей, должны быть уникальными, неизменяемыми и всегда заполненными (никогда не NULL или пустыми). По этой причине номера заказов и имена пользователей подходят на роль первичных ключей, в отличие от номеров телефонов или адресов. Вы также можете использовать несколько полей в сочетании в качестве первичного ключа (это называется составным ключом).
Когда придет время создавать реальную базу данных, вы перенесете логическую и физическую структуры данных на язык определения данных, поддерживаемый вашей СУБД. На этом этапе также следует оценить размер базы данных, чтобы убедиться в обеспечении требуемого уровня производительности и объема хранилища.
Создание связей между сущностями
Теперь, когда списки данных превратились в таблицы, вы готовы проанализировать связи между ними. Кратность связей (кардинальность) указывает на количество элементов, взаимодействующих между двумя связанными таблицами. Определение кратности помогает убедиться, что данные разделены по таблицам наиболее эффективным способом.
Каждая сущность потенциально может иметь связь с любой другой, но обычно эти связи относятся к одному из трех типов:
Связи «один к одному»
Когда для каждого экземпляра сущности А существует только один экземпляр сущности Б, говорят, что они имеют связь «один к одному» (часто записывается как 1:1). Вы можете обозначить такой тип связи на ER-диаграмме линией со штрихом на каждом конце:

Если для этого нет веских причин, связь 1:1 обычно указывает на то, что данные из этих двух таблиц лучше объединить в одну.
Тем не менее, создание таблиц со связью 1:1 может быть оправдано при определенных обстоятельствах. Если у вас есть поле с необязательными данными (например, «описание»), которое остается пустым для многих записей, вы можете вынести все описания в отдельную таблицу, что устранит пустые пространства и повысит производительность базы данных.
Чтобы гарантировать корректное сопоставление данных, вам потребуется включить как минимум один идентичный столбец в каждую таблицу — скорее всего, первичный ключ.
Связи «один ко многим»
Такие связи возникают, когда одна запись в одной таблице связана с несколькими записями в другой. Например, один клиент может сделать много заказов, или читатель библиотеки может одновременно взять несколько книг. Связи «один ко многим» (1:M) обозначаются так называемой нотацией «гусиная лапка» (Crow's foot), как в этом примере:

Чтобы реализовать связь 1:M при настройке базы данных, просто добавьте первичный ключ со стороны «один» в качестве атрибута в другую таблицу. Когда первичный ключ указывается в другой таблице таким образом, он называется внешним ключом. Таблица на стороне «1» считается родительской, а таблица на другой стороне — дочерней.
Связи «многие ко многим»
Когда несколько сущностей из одной таблицы могут быть связаны с несколькими сущностями из другой, говорят, что они имеют связь «многие ко многим» (M:N). Это часто происходит в случае со студентами и учебными курсами, так как один студент может посещать множество курсов, а на одном курсе может учиться много студентов.
На ER-диаграмме такие связи изображаются следующими линиями:

К сожалению, напрямую реализовать такой тип связи в базе данных невозможно. Вместо этого её приходится разбивать на две связи «один ко многим».
Для этого создайте новую сущность между этими двумя таблицами. Если связь M:N существует между продажами и товарами, вы можете назвать новую сущность «проданные_товары», так как она будет отражать содержимое каждой продажи. Обе таблицы (продажи и товары) будут иметь связь 1:M с таблицей «проданные_товары». Такое промежуточное звено в различных моделях называют связующей таблицей, ассоциативной сущностью или таблицей соединений.
Каждая запись в связующей таблице будет сопоставлять две сущности из соседних таблиц (она также может содержать дополнительную информацию). Например, связующая таблица между студентами и курсами может выглядеть так:

Обязательная связь или нет?
Еще один способ анализа связей — определить, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии вместо штриха. Например, страна должна существовать, чтобы иметь представителя в ООН, но обратное неверно:

Две сущности также могут быть взаимозависимыми (одна не может существовать без другой).
Рекурсивные связи
Иногда таблица ссылается сама на себя. Например, таблица сотрудников может содержать атрибут «руководитель», который ссылается на другого человека в этой же таблице. Это называется рекурсивной связью.
Избыточные связи
Избыточная связь — это связь, которая выражена более одного раза. Обычно одну из таких связей можно удалить без потери важной информации. Например, если сущность «студенты» имеет прямую связь с сущностью «преподаватели», но также косвенно связана с ними через «курсы», прямую связь между студентами и преподавателями целесообразно удалить. Ее удаление предпочтительно, поскольку студенты назначаются к преподавателям исключительно через курсы.
Нормализация баз данных
После создания предварительного проекта базы данных вы можете применить правила нормализации, чтобы убедиться в правильности структуры таблиц. Считайте эти правила отраслевыми стандартами.
Тем не менее, не все базы данных подходят для нормализации. Как правило, базы данных для оперативной обработки транзакций (OLTP), где пользователи создают, читают, обновляют и удаляют записи, должны быть нормализованы.
Базы данных для аналитической обработки в реальном времени (OLAP), ориентированные на анализ и отчетность, могут выиграть от определенной степени денормализации, поскольку для них важнее скорость вычислений. Сюда относятся приложения поддержки принятия решений, в которых данные необходимо анализировать быстро, но не изменять.
Каждая форма, или уровень нормализации, включает в себя правила, связанные с более низкими формами.
Первая нормальная форма
Первая нормальная форма (1NF) предписывает, что каждая ячейка таблицы может содержать только одно значение и никогда — список значений. Таким образом, подобная таблица не соответствует правилу:
| ProductID | Color | Price |
|---|
| 1 | brown, yellow | $15 |
| 2 | red, green | $13 |
| 3 | blue, orange | $11 |
Может возникнуть соблазн обойти это правило, разделив данные на дополнительные столбцы, но это также противоречит стандартам: таблица с группами повторяющихся или близких по смыслу атрибутов не соответствует первой нормальной форме. Приведенная ниже таблица нарушает это правило:

Вместо этого разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение и не исчезнут лишние столбцы. В этот момент данные считаются атомарными, то есть разбитыми до минимально полезного размера. Для таблицы выше можно создать дополнительную таблицу «Детали продаж», которая будет сопоставлять конкретные товары с продажами. В таком случае «Продажи» будут иметь связь 1:M с «Деталями продаж».
Вторая нормальная форма
Вторая нормальная форма (2NF) требует, чтобы каждый из атрибутов полностью зависел от всего первичного ключа. Это означает, что каждый атрибут должен зависеть от первичного ключа напрямую, а не косвенно через какой-то другой атрибут.
Например, если атрибут «возраст» зависит от «даты рождения», которая, в свою очередь, зависит от «ID_студента», это называется частичной функциональной зависимостью, и таблица с такими атрибутами не будет соответствовать второй нормальной форме.
Кроме того, таблица с составным первичным ключом (состоящим из нескольких полей) нарушает вторую нормальную форму, если одно или несколько других полей не зависят от каждой части этого ключа.
Таким образом, таблица со следующими полями не будет соответствовать второй нормальной форме, так как атрибут «название товара» зависит от ID товара, но не зависит от номера заказа:
Третья нормальная форма
Третья нормальная форма (3NF) добавляет к этим правилам требование, чтобы каждый неключевой столбец был независим от любого другого столбца. Если изменение значения в одном неключевом столбце приводит к изменению значения в другом, такая таблица не соответствует третьей нормальной форме.
Это исключает хранение любых производных данных в таблице, таких как столбец «налог» ниже, который напрямую зависит от общей цены заказа:
| Order | Price | Tax |
| 14325 | $40.99 | $2.05 |
| 14326 | $13.73 | $.69 |
| 14327 | $24.15 | $1.21 |
Были предложены и дополнительные формы нормализации, включая нормальную форму Бойса-Кодда, с четвертой по шестую нормальные формы, а также доменно-ключевую нормальную форму, но первые три являются самыми распространенными.
Хотя эти формы описывают общие рекомендации, степень нормализации всегда зависит от контекста и назначения базы данных.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким измерениям одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиентам, регионам и месяцам. В такой ситуации лучше всего создать центральную таблицу фактов, на которую смогут ссылаться другие таблицы клиентов, регионов и месяцев, как здесь:

Правила целостности данных
Вам также следует настроить базу данных для проверки данных в соответствии с надлежащими правилами. Многие СУБД, такие как Microsoft Access, принудительно применяют некоторые из этих правил автоматически.
Правило целостности сущностей гласит, что первичный ключ никогда не может быть NULL. Если ключ состоит из нескольких столбцов, ни один из них не может быть NULL. В противном случае ключ не сможет однозначно идентифицировать запись.
Правило ссылочной целостности требует, чтобы каждый внешний ключ, указанный в одной таблице, соответствовал одному первичному ключу в той таблице, на которую он ссылается. Если первичный ключ изменяется или удаляется, эти изменения необходимо будет применить везде, где на этот ключ есть ссылки в базе данных.
Правила целостности бизнес-логики гарантируют, что данные соответствуют определенным логическим параметрам. Например, время встречи должно укладываться в стандартные рабочие часы.
Добавление индексов и представлений
Индекс — это, по сути, отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет пользователям находить записи быстрее. Вместо повторной сортировки для каждого запроса система может получать доступ к записям в порядке, указанном индексом.
Хотя индексы ускоряют извлечение данных, они могут замедлить вставку, обновление и удаление, поскольку при каждом изменении записи индекс приходится перестраивать.
Представление (view) — это просто сохраненный запрос к данным. Они могут эффективно объединять данные из нескольких таблиц или показывать часть одной таблицы.
Расширенные свойства
После завершения базовой структуры вы можете доработать базу данных с помощью расширенных свойств, таких как пояснительный текст, маски ввода и правила форматирования, применимые к конкретной схеме, представлению или столбцу. Преимущество заключается в том, что, поскольку эти правила хранятся в самой базе данных, представление данных будет согласованным во всех программах, обращающихся к ним.
SQL и UML
Унифицированный язык моделирования (UML) — это еще один визуальный способ выражения сложных систем, созданных на объектно-ориентированном языке. Некоторые понятия, упомянутые в данном руководстве, известны в UML под другими названиями. Например, сущность в UML называется классом.
Сегодня UML используется не так часто, как раньше. В настоящее время он чаще применяется в академических кругах и при взаимодействии между разработчиками программного обеспечения и их клиентами.
Системы управления базами данных
Многие решения по проектированию зависят от того, какую систему управления базами данных вы используете. К числу наиболее распространенных систем относятся:
-
Oracle DB
-
MySQL
-
Microsoft SQL Server
-
PostgreSQL
-
IBM DB2
При наличии выбора подбирайте подходящую СУБД с учетом стоимости, операционных систем, функций и других факторов.
Схема в СУБД Oracle
В СУБД Oracle термин схема базы данных (также известный как «SQL-схема») имеет иное значение. Здесь база данных может содержать несколько схем. Каждая из них содержит все объекты, созданные конкретным пользователем базы данных. Эти объекты могут включать таблицы, представления, синонимы и многое другое. Некоторые объекты не могут быть включены в схему, например пользователи, контексты, роли и объекты каталогов.

Пользователям может быть предоставлен доступ для входа в отдельные схемы в индивидуальном порядке, а право владения может передаваться. Поскольку каждый объект связан с определенной схемой, которая служит своего рода пространством имен, полезно настроить синонимы — это позволит другим пользователям получать доступ к объекту без предварительного указания схемы, к которой он принадлежит.
Эти схемы не обязательно указывают на то, как файлы данных хранятся физически. Вместо этого объекты схемы хранятся логически внутри табличного пространства. Администратор базы данных может указать, сколько места выделить конкретному объекту в файле данных.
Наконец, схемы и табличные пространства не обязательно идеально совпадают: объекты из одной схемы могут находиться в нескольких табличных пространствах, в то время как одно табличное пространство может включать объекты из нескольких схем.
Экземпляр базы данных или схема базы данных?
These terms, though related, do not mean the same thing. А схема базы данных — это проект планируемой базы данных. В ней еще нет никаких реальных данных.
Экземпляр (инстанс) базы данных, с другой стороны, представляет собой снимок состояния базы данных в определенный момент времени. Таким образом, экземпляры баз данных могут меняться со временем, тогда как схема базы данных обычно статична, поскольку структуру базы данных трудно изменить после ввода в эксплуатацию.
Схемы баз данных и экземпляры баз данных могут влиять друг на друга через систему управления базами данных (СУБД). СУБД следит за тем, чтобы каждый экземпляр базы данных соответствовал ограничениям, наложенным проектировщиками в схеме базы данных.
Требования к интеграции схем
Иногда полезно интегрировать несколько источников в одну схему. Для плавного перехода убедитесь, что соблюдены следующие требования:
Сохранение пересечений
Каждый пересекающийся элемент в интегрируемых схемах должен присутствовать в таблице схемы базы данных.
Расширенное сохранение пересечений
Элементы, которые появляются только в одном источнице, но связаны с пересекающимися элементами, должны быть перенесены в итоговую схему базы данных.
Нормализация
Независимые связи и сущности не должны объединяться в одной таблице схемы базы данных.
Минимальность
В идеале ни один из элементов ни в одном из источников не должен быть утерян.
Типы схем баз данных
При проектировании схем баз данных сложились определенные шаблоны.
Широко используемая схема «звезда» является одновременно и самой простой. В ней одна или несколько таблиц фактов связаны с любым количеством таблиц измерений. Она лучше всего подходит для обработки простых запросов.
Связанная схема «снежинка» также используется для представления многомерных баз данных. Однако в этом шаблоне измерения нормализуются в множество отдельных таблиц, что создает разветвленный эффект, напоминающий структуру снежинки.