Análisis de requisitos: identificación del propósito de la base de datos
Comprender el propósito de tu base de datos guiará tus decisiones a lo largo del proceso de diseño. Asegúrate de considerar la base de datos desde todas las perspectivas. Por ejemplo, si estuvieras creando una base de datos para una biblioteca pública, tendrías que considerar las formas en que tanto los usuarios como los bibliotecarios necesitarían acceder a los datos.
Aquí tienes algunas formas de recopilar información antes de crear la base de datos:
- Entrevista a las personas que la usarán
- Analiza los formularios comerciales, como facturas, hojas de horas, encuestas
- Revisa cualquier sistema de datos existente (incluidos los archivos físicos y digitales)
Comienza por recopilar todos los datos existentes que se incluirán en la base de datos. Luego, enumera los tipos de datos que deseas almacenar y las entidades, o personas, cosas, ubicaciones y eventos que describen esos datos, de esta manera:
Clientes
- Nombre
- Dirección
- Ciudad, estado, código postal
- Dirección de correo electrónico
Productos
- Nombre
- Precio
- Cantidad en stock
- Cantidad bajo pedido
Pedidos
- ID del pedido
- Representante de ventas
- Fecha
- Producto(s)
- Cantidad
- Precio
- Total
Esta información pasará a formar parte más adelante del diccionario de datos, que describe las tablas y los campos dentro de la base de datos. Asegúrate de desglosar la información en los fragmentos útiles más pequeños posibles. Por ejemplo, considera separar la dirección de la calle del país para poder filtrar posteriormente a las personas por su país de residencia. Además, evita colocar el mismo dato en más de una tabla, lo que añade complejidad innecesaria.
Una vez que sepas qué tipos de datos incluirá la base de datos, de dónde provienen y cómo se utilizarán, estarás listo para comenzar a planificar la base de datos real.
Estructura de la base de datos: los componentes básicos de una base de datos
El siguiente paso es trazar una representación visual de tu base de datos. Para hacer eso, necesitas entender exactamente cómo se estructuran las bases de datos relacionales.
Dentro de una base de datos, los datos relacionados se agrupan en tablas, cada una de las cuales consta de filas (también llamadas tuplas) y columnas, como una hoja de cálculo.
Para convertir tus listas de datos en tablas, comienza por crear una tabla para cada tipo de entidad, como productos, ventas, clientes y pedidos. Aquí tienes un ejemplo:
Cada fila de una tabla se denomina registro. Los registros incluyen datos sobre algo o alguien, como un cliente en particular. Por el contrario, las columnas (también conocidas como campos o atributos) contienen un solo tipo de información que aparece en cada registro, como las direcciones de todos los clientes enumerados en la tabla.
| Nombre | Apellido | Edad | Código postal |
|---|
| Roger | Williams | 43 | 34760 |
| Jerrica | Jorgensen | 32 | 97453 |
| Samantha | Hopkins | 56 | 64829 |
To keep the data consistent from one record to the next, assign the appropriate data type to each column. Common data types include:
- CHAR: una longitud de texto específica
- VARCHAR: texto de longitudes variables
- TEXT: grandes cantidades de texto
- INT: número entero positivo o negativo
- FLOAT, DOUBLE: también pueden almacenar números de punto flotante
- BLOB: datos binarios
Algunos sistemas de gestión de bases de datos también ofrecen el tipo de datos Autonumeración, que genera automáticamente un número único en cada fila.
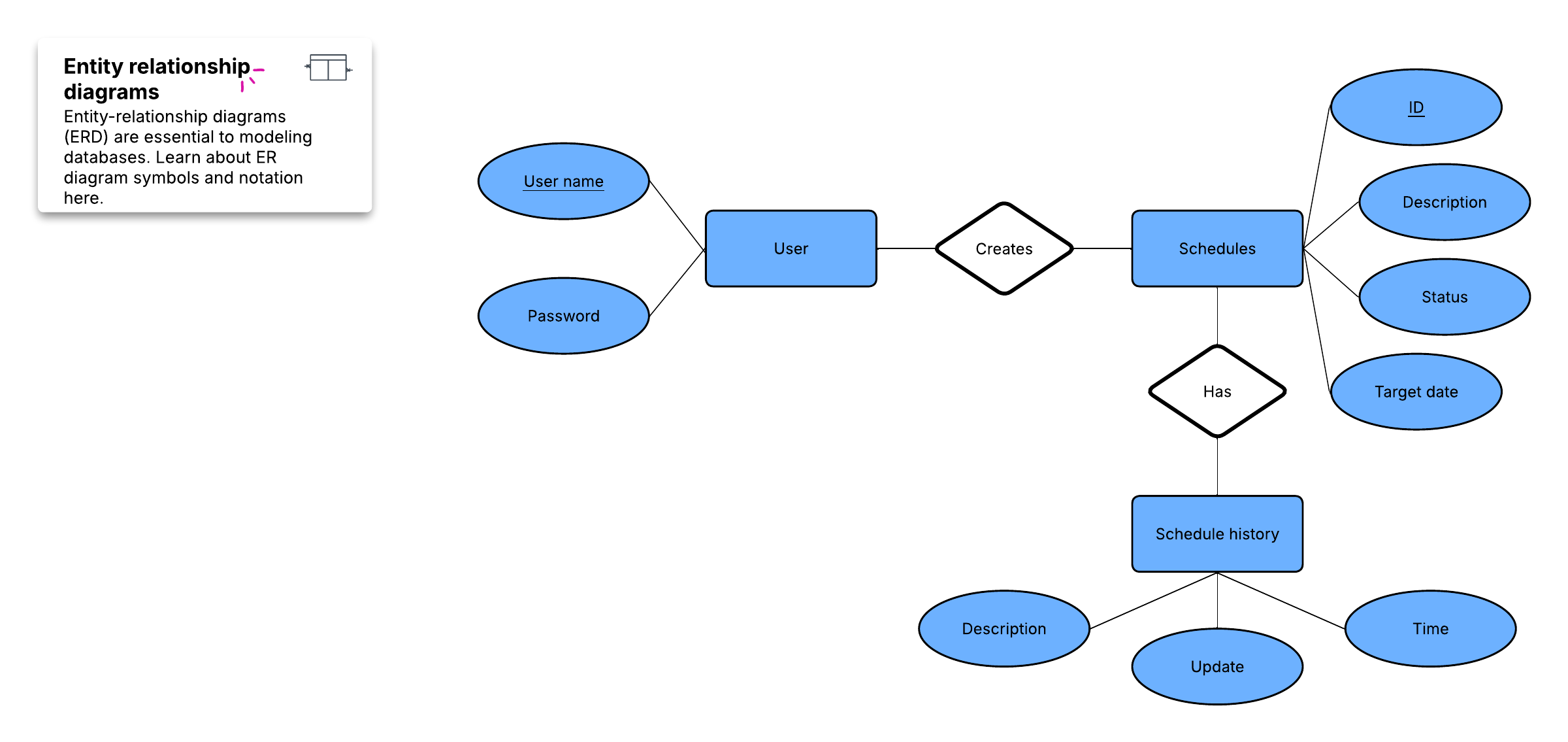
Para los propósitos de crear un panorama general visual de la base de datos, conocido como diagrama de entidad-relación, no incluirás las tablas reales. En su lugar, cada tabla se convierte en un cuadro en el diagrama. El título de cada cuadro debe indicar lo que describen los datos de esa tabla, mientras que los atributos se enumeran a continuación, de esta manera:

Finalmente, debes decidir qué atributo o atributos servirán como clave primaria para cada tabla, si corresponde. Una clave primaria (PK) es un identificador único para una entidad determinada, lo que significa que podrías identificar a un cliente exacto incluso si solo conocieras ese valor.
Los atributos elegidos como claves primarias deben ser únicos, invariables y estar siempre presentes (nunca NULL ni vacíos). Por esta razón, los números de pedido y los nombres de usuario son buenas claves primarias, mientras que los números de teléfono o las direcciones de las calles no lo son. También puedes utilizar varios campos de forma conjunta como clave primaria (esto se conoce como clave compuesta).
Cuando llegue el momento de crear la base de datos real, colocarás tanto la estructura de datos lógica como la estructura de datos física en el lenguaje de definición de datos admitido por tu sistema de gestión de bases de datos. En ese punto, también debes estimar el tamaño de la base de datos para asegurarte de que puedes obtener el nivel de rendimiento y el espacio de almacenamiento que requerirá.
Creación de relaciones entre entidades
Con tus listas de datos ahora convertidas en tablas, estás listo para analizar las relaciones entre esas tablas. La cardinalidad se refiere a la cantidad de elementos que interactúan entre dos tablas relacionadas. Identificar la cardinalidad ayuda a asegurarse de haber dividido los datos en tablas de la manera más eficiente.
Cada entidad puede tener potencialmente una relación con cualquier otra, pero esas relaciones suelen ser de uno de tres tipos:
Relaciones uno a uno
Cuando solo hay una instancia de la Entidad A por cada instancia de la Entidad B, se dice que tienen una relación uno a uno (a menudo escrita como 1:1). Puedes indicar este tipo de relación en un diagrama ER con una línea con un guion en cada extremo:

A menos que tengas una buena razón para no hacerlo, una relación 1:1 suele indicar que sería mejor combinar los datos de las dos tablas en una sola tabla.
Sin embargo, es posible que desees crear tablas con una relación 1:1 bajo un conjunto particular de circunstancias. Si tienes un campo con datos opcionales, como "descripción", que está en blanco para muchos de los registros, puedes mover todas las descripciones a su propia tabla, eliminando el espacio vacío y mejorando el rendimiento de la base de datos.
Para garantizar que los datos coincidan correctamente, tendrías que incluir al menos una columna idéntica en cada tabla, muy probablemente la clave primaria.
Relaciones uno a varios
Estas relaciones ocurren cuando un registro de una tabla se asocia con varias entradas de otra. Por ejemplo, un solo cliente puede haber realizado muchos pedidos, o un usuario de la biblioteca puede tener varios libros prestados a la vez. Las relaciones uno a varios (1:M) se indican con lo que se llama "notación de pata de gallo", como en este ejemplo:

Para implementar una relación 1:M al configurar una base de datos, simplemente añade la clave primaria del lado "uno" de la relación como un atributo en la otra tabla. Cuando una clave primaria se enumera en otra tabla de esta manera, se denomina clave foránea. La tabla del lado "1" de la relación se considera una tabla madre de la tabla hija del otro lado.
Relaciones varios a varios
Cuando varias entidades de una tabla se pueden asociar con varias entidades de otra tabla, se dice que tienen una relación varios a varios (M:N). Esto podría suceder en el caso de estudiantes y clases, ya que un estudiante puede tomar muchas clases y una clase puede tener muchos estudiantes.
En un diagrama ER, estas relaciones se representan con estas líneas:

Desafortunadamente, no es posible implementar directamente este tipo de relación en una base de datos. En su lugar, tienes que dividirla en dos relaciones uno a varios.
Para hacerlo, crea una nueva entidad entre esas dos tablas. Si la relación M:N existe entre ventas y productos, podrías llamar a esa nueva entidad "productos_vendidos", ya que mostraría el contenido de cada venta. Tanto la tabla de ventas como la de productos tendrían una relación 1:M con productos_vendidos. Este tipo de entidad intermedia se denomina tabla de enlace, entidad asociativa o tabla de unión en varios modelos.
Cada registro en la tabla de enlace coincidiría con dos de las entidades en las tablas vecinas (también puede incluir información complementaria). Por ejemplo, una tabla de enlace entre estudiantes y clases podría verse así:

¿Obligatoria o no?
Otra forma de analizar las relaciones es considerar qué lado de la relación tiene que existir para que el otro exista. El lado no obligatorio se puede marcar con un círculo en la línea donde iría un guion. Por ejemplo, un país tiene que existir para tener un representante en las Naciones Unidas, pero lo contrario no es cierto:

Dos entidades pueden ser mutuamente dependientes (una no podría existir sin la otra).
Relaciones recursivas
A veces, una tabla apunta hacia sí misma. Por ejemplo, una tabla de empleados puede tener un atributo "gerente" que se refiere a otra persona en esa misma tabla. Esto se denomina relación recursiva.
Relaciones redundantes
Una relación redundante es aquella que se expresa más de una vez. Por lo general, puedes eliminar una de las relaciones sin perder ninguna información importante. Por ejemplo, si una entidad "estudiantes" tiene una relación directa con otra llamada "profesores" pero también tiene una relación con los profesores de forma indirecta a través de "clases", querrás eliminar la relación entre "estudiantes" y "profesores". Es mejor eliminar esa relación porque la única forma en que los estudiantes se asignan a los profesores es a través de las clases.
Normalización de bases de datos
Una vez que tengas un diseño preliminar para tu base de datos, puedes aplicar reglas de normalización para asegurarte de que las tablas estén estructuradas correctamente. Piensa en estas reglas como los estándares de la industria.
Dicho esto, no todas las bases de datos son buenas candidatas para la normalización. En general, las bases de datos de procesamiento de transacciones en línea (OLTP, por sus siglas en inglés), en las que los usuarios se preocupan por crear, leer, actualizar y eliminar registros, deben normalizarse.
Las bases de datos de procesamiento analítico en línea (OLAP) que favorecen el análisis y los informes podrían funcionar mejor con un grado de desnormalización, ya que el énfasis está en la velocidad de cálculo. Estas incluyen aplicaciones de soporte de decisiones en las que los datos deben analizarse rápidamente pero no modificarse.
Cada forma, o nivel de normalización, incluye las reglas asociadas con las formas inferiores.
Primera forma normal
La primera forma normal (abreviada como 1NF) especifica que cada celda de la tabla puede tener un solo valor, nunca una lista de valores, por lo que una tabla como esta no cumple con la regla:
| ID del producto | Color | Precio |
|---|
| 1 | marrón, amarillo | $15 |
| 2 | rojo, verde | $13 |
| 3 | azul, naranja | $11 |
Podrías tener la tentación de solucionar esto dividiendo esos datos en columnas adicionales, pero eso también va en contra de las reglas: una tabla con grupos de atributos repetidos o estrechamente relacionados no cumple con la primera forma normal. La siguiente tabla, por ejemplo, no cumple con la regla:

En su lugar, divide los datos en varias tablas o registros hasta que cada celda contenga un solo valor y no haya columnas adicionales. En ese punto, se dice que los datos son atómicos, o desglosados al tamaño útil más pequeño. Para la tabla anterior, podrías crear una tabla adicional llamada "Detalles de ventas" que haría coincidir productos específicos con las ventas. "Ventas" tendría entonces una relación 1:M con "Detalles de ventas".
Segunda forma normal
La segunda forma normal (2NF) exige que cada uno de los atributos dependa por completo de toda la clave primaria. Eso significa que cada atributo debe depender directamente de la clave primaria, en lugar de hacerlo indirectamente a través de algún otro atributo.
Por ejemplo, se dice que un atributo "edad" que depende de "fecha de nacimiento" que a su vez depende de "ID del estudiante" tiene una dependencia funcional parcial, y una tabla que contenga estos atributos no cumpliría con la segunda forma normal.
Además, una tabla con una clave primaria compuesta por varios campos infringe la segunda forma normal si uno o más de los otros campos no dependen de cada parte de la clave.
Por lo tanto, una tabla con estos campos no cumpliría con la segunda forma normal, porque el atributo "nombre del producto" depende del ID del producto pero no del número de pedido:
Tercera forma normal
La tercera forma normal (3NF) añade a estas reglas el requisito de que cada columna que no sea clave sea independiente de todas las demás columnas. Si el cambio de un valor en una columna que no es clave hace que cambie otro valor, esa tabla no cumple con la tercera forma normal.
Esto evita que almacenes datos derivados en la tabla, como la columna "impuesto" a continuación, que depende directamente del precio total del pedido:
| Pedido | Precio | Impuesto |
| 14325 | $40.99 | $2.05 |
| 14326 | $13.73 | $.69 |
| 14327 | $24.15 | $1.21 |
Se han propuesto formas adicionales de normalización, incluida la forma normal de Boyce-Codd, de la cuarta a la sexta forma normal y la forma normal de clave de dominio, pero las tres primeras son las más comunes.
Si bien estas formas explican las mejores prácticas a seguir en general, el grado de normalización depende del contexto de la base de datos.
Datos multidimensionales
Es posible que algunos usuarios deseen acceder a múltiples dimensiones de un solo tipo de datos, particularmente en bases de datos OLAP. Por ejemplo, es posible que deseen conocer las ventas por cliente, estado y mes. In esta situación, lo mejor es crear una tabla de hechos central a la que puedan hacer referencia otras tablas de clientes, estados y meses, como esta:

Reglas de integridad de datos
También debes configurar tu base de datos para validar los datos de acuerdo con las reglas adecuadas. Muchos sistemas de gestión de bases de datos, como Microsoft Access, aplican algunas de estas reglas automáticamente.
La regla de integridad de la entidad dice que la clave primaria nunca puede ser NULL. Si la clave está compuesta por varias columnas, ninguna de ellas puede ser NULL. De lo contrario, podría no identificar de forma única el registro.
La regla de integridad referencial requiere que cada clave foránea enumerada en una tabla coincida con una clave primaria en la tabla que hace referencia. Si la clave primaria cambia o se elimina, esos cambios deberán implementarse en todos los lugares donde se haga referencia a esa clave en toda la base de datos.
Las reglas de integridad de la lógica empresarial aseguran que los datos se ajusten a ciertos parámetros lógicos. Por ejemplo, la hora de una cita tendría que caer dentro del horario comercial normal.
Adición de índices y vistas
Un índice es esencialmente una copia ordenada de una o más columnas, con los valores en orden ascendente o descendente. Añadir un índice permite a los usuarios encontrar registros más rápidamente. En lugar de volver a ordenar para cada consulta, el sistema puede acceder a los registros en el orden especificado por el índice.
Aunque los índices aceleran la recuperación de datos, pueden ralentizar la inserción, actualización y eliminación, ya que el índice debe reconstruirse cada vez que se cambia un registro.
Una vista es simplemente una consulta guardada sobre los datos. Pueden unir de manera útil datos de varias tablas o mostrar una parte de una tabla.
Propiedades extendidas
Una vez que hayas completado el diseño básico, puedes refinar la base de datos con propiedades extendidas, como texto de instrucciones, máscaras de entrada y reglas de formato que se aplican a un esquema, vista o columna en particular. La ventaja es que, debido a que estas reglas se almacenan en la propia base de datos, la presentación de los datos será coherente en los múltiples programas que acceden a ellos.
SQL y UML
El lenguaje unificado de modelado (UML) es otra forma visual de expresar sistemas complejos creados en un lenguaje orientado a objetos. Varios de los conceptos mencionados en esta guía se conocen en UML con nombres diferentes. Por ejemplo, una entidad se conoce como una clase en UML.
UML no se utiliza hoy en día con tanta frecuencia como antes. Actualmente, a menudo se usa académicamente y en las comunicaciones entre los diseñadores de software y sus clientes.
Sistemas de gestión de bases de datos
Muchas de las opciones de diseño que elijas dependerán del sistema de gestión de bases de datos que utilices. Algunos de los sistemas más comunes incluyen:
-
Oracle DB
-
MySQL
-
Microsoft SQL Server
-
PostgreSQL
-
IBM DB2
Cuando tengas la opción, elige un sistema de gestión de bases de datos adecuado según el costo, los sistemas operativos, las características y más.
Esquema en el sistema de base de datos Oracle
En el sistema de base de datos Oracle, el término esquema de base de datos, que también se conoce como "esquema SQL", tiene un significado diferente. Aquí, una base de datos puede tener múltiples esquemas. Cada uno contiene todos los objetos creados por un usuario específico de la base de datos. Esos objetos pueden incluir tablas, vistas, sinónimos y más. Algunos objetos no se pueden incluir en un esquema, como los usuarios, los contextos, los roles y los objetos de directorio.

A los usuarios se les puede otorgar acceso para iniciar sesión en esquemas individuales caso por caso, y la propiedad es transferible. Dado que cada objeto está asociado con un esquema particular, que sirve como una especie de espacio de nombres, es útil dar algunos sinónimos, lo que permite a otros usuarios acceder a ese objeto sin hacer referencia primero al esquema al que pertenece.
Estos esquemas no indican necesariamente las formas en que los archivos de datos se almacenan físicamente. En su lugar, los objetos de esquema se almacenan lógicamente dentro de un espacio de tablas (tablespace). El administrador de la base de datos puede especificar cuánto espacio asignar a un objeto en particular dentro de un archivo de datos.
Finalmente, los esquemas y los espacios de tablas no se alinean necesariamente a la perfección: los objetos de un esquema se pueden encontrar en varios espacios de tablas, mientras que un espacio de tablas puede incluir objetos de varios esquemas.
¿Instancia de base de datos o esquema de base de datos?
Estos términos, aunque están relacionados, no significan lo mismo. Un esquema de base de datos es un diseño de una base de datos planificada. En realidad no contiene ningún dato.
Una instancia de base de datos, por otro lado, es una instantánea de una base de datos tal como existía en un momento determinado. Por lo tanto, las instancias de bases de datos pueden cambiar con el tiempo, mientras que un esquema de base de datos suele ser estático, ya que es difícil cambiar la estructura de una base de datos una vez que está operativa.
Los esquemas de bases de datos y las instancias de bases de datos pueden afectarse mutuamente a través de un sistema de gestión de bases de datos (DBMS). El DBMS se asegura de que cada instancia de base de datos cumpla con las restricciones impuestas por los diseñadores de la base de datos en el esquema de la base de datos.
Requisitos de integración de esquemas
Puede ser útil integrar múltiples fuentes en un solo esquema. Asegúrate de que se cumplan estos requisitos para una transición sin problemas:
Preservación de la superposición
Cada elemento superpuesto en los esquemas que estás integrando debe estar en una tabla de esquema de base de datos.
Preservación extendida de la superposición
Los elementos que solo aparecen en una fuente, pero que están asociados con elementos superpuestos, deben copiarse en el esquema de base de datos resultante.
Normalización
Las relaciones y entidades independientes no deben agruparse en la misma tabla en el esquema de la base de datos.
Minimalidad
Lo ideal es que no se pierda ninguno de los elementos de ninguna de las fuentes.
Tipos de esquemas de bases de datos
Se han desarrollado ciertos patrones en el diseño de esquemas de bases de datos.
El esquema de estrella, ampliamente utilizado, es también el más simple. En él, una o más tablas de hechos están vinculadas a cualquier número de tablas dimensionales. Es ideal para manejar consultas simples.
El esquema de copo de nieve relacionado también se utiliza para representar una base de datos multidimensional. En este patrón, sin embargo, las dimensiones se normalizan en muchas tablas separadas, lo que crea el efecto expansivo de una estructura similar a un copo de nieve.