Lucid Software is the leader in visual collaboration and work acceleration, helping teams see and build the future by turning ideas into reality. Its products include the Lucid Visual Collaboration Suite (Lucidchart and Lucidspark) and airfocus. The Lucid Visual Collaboration Suite, combined with powerful accelerators for cloud and process transformation, empowers organizations to streamline work, foster alignment, and drive business transformation at scale. airfocus, an AI-powered product management and roadmapping platform, extends these capabilities by helping teams prioritize work, define product strategy, and align execution with business goals. The most used work acceleration platform by the Fortune 500, Lucid's solutions are trusted by more than 100 million users across enterprises worldwide, including Google, GE, and NBC Universal. Lucid partners with leaders such as Google, Atlassian, and Microsoft, and has received numerous awards for its products, growth, and workplace culture.
As any SaaS engineer can tell you, things that are simple in a single user scenario can easily balloon out of control when many users need to be accounted for. Take the simplest use case imaginable: editing a file. In a single-user scenario, it’s easy as pie. Read the bits, change some bits, write the bits. Done.
When you introduce a few more users that can edit the same file at the same time, things get trickier—and before long, you’ve written some subset of git. Now add in the stipulation that users need to be able to access their files from any machine, and you need to highlight not-yet-viewed file changes. Suddenly you’re looking at an O(nm) storage problem: each file has to store n chunks of information about m users.
We ran into this problem while revamping the commenting and notifications features in Lucidchart. Curious to know how we tackled it? Read on for details.
Background
Lucidchart is a cloud-based collaborative diagramming application, so features that enable our users to collaborate effectively are a must. We've had a commenting system in place for some time, but it has been plagued by pain points like users having to manually check each document for new comments instead of being automatically notified. Our goal was to alleviate those kinds of problems with the commenting system by building an extensible notification system, which would initially focus on notifications about unread comments. It turns out that doing this is not trivial.
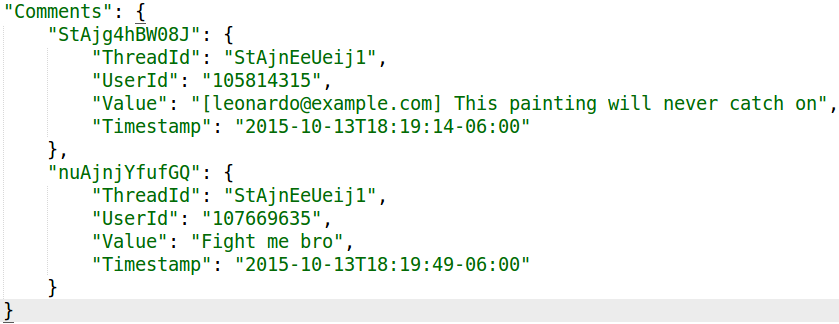
JSON representation of comments in a Lucidchart document
The Problem
Let's imagine that all users are connected at all times. Whenever a user submits a new comment, we push a notification to all collaborating users about that new comment, and let's further assume that every user clicks the notification and reads the comment immediately. In this perfect world, the server can take a fire-and-forget approach to notifications, and we don't need to store any extra notification data on the server. Obviously, this is not the case in the real world.
Back in reality, users log in and out at their leisure, and even if we send them a notification, they don't necessarily read it immediately. Instead, we have to store data about it for each user until they do read it. The O(nm) problem has begun to appear: we have to store a "seen/unseen" flag for each of n new comments, for each of m collaborators. This means that unless we find a cheat of some kind, we're stuck with a bad space complexity requirement.
(As an aside, we could store those flags alongside the comment in the corresponding diagram file, but that would be a terrible mistake: the flags don't actually have anything to do with document state, so they bloat the diagram's file size unnecessarily, which kills our load time.)
Staking out a Solution
Outside of the document itself, we have two other places we can store the notification data: in another table in a server-side database or in the browser’s local storage. Local storage is always alluring because it’s easy to use and it’s free, but it has the unfortunate drawback of being device-specific: if you read a bunch of comments on your work computer, your personal laptop won’t know anything about that and will display those comments as if they’ve never been read. With this in mind, we went with the database option, but we also used local storage to get the best of both worlds.
We operated under 3 primary constraints:
Save as little as possible in local storage and the database
Rely on real-time notifications as much as possible
In the case of failure, err on the side of marking comments as unread
The first constraint is straightforward: we don’t want to store anything unnecessarily. As for the second, our preference to rely on real-time notifications comes from the fact that we get real-time notifications basically for free just by having real-time commenting (which already existed), and we want to give users their notifications as early as possible. For failure modes, we reasoned that in the (hopefully rare) case where we have a notification hiccup, users would usually prefer to see a notification twice than to miss a notification.
All comments seenUnread comments present
To give a bit more detail, when a user receives a new comment, the Javascript code creates it and automatically marks it as unread, which means that it displays with a little red icon. Since any comment added to the document after loading can be treated as unread by the client, the server doesn’t have to do any extra work or store any additional data for this to happen. We just have to remember that even if the client successfully received a notification (i.e. the icon turned red), it doesn’t necessarily mean that the user actually clicked the comment panel and read the comment, so we must still proceed on the server as if they haven’t yet read it.
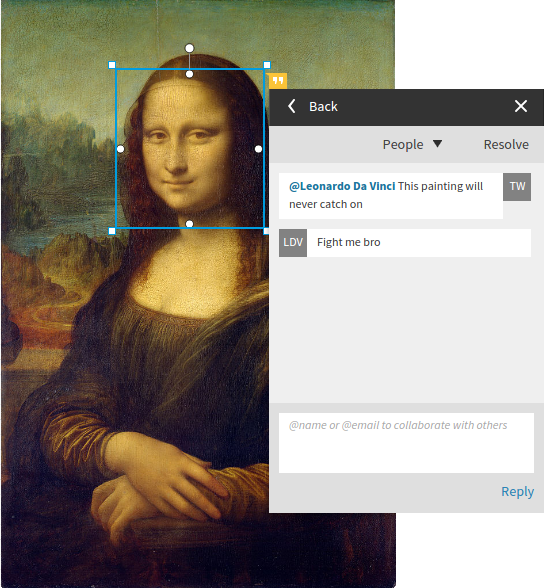
You may recall that the storage cost of notification data is O(nm), no matter where we put it. There isn’t a whole lot we can do about that; it’s pretty straightforward that we have m agents and n pieces of information to store about each agent, but in this case (and most likely yours, if you’re writing a comment notification system) we can make use of a convenient property of the information we need to store: one of its two states is a “black hole” state (meaning it can’t be left once it has been entered). Although a comment can be in an unread state, you can’t un-read a comment once you’ve read it, any more than you can un-see the Mona Lisa once you’ve seen it.
A hapless commenter about to get a history lesson from Leonardo da Vinci
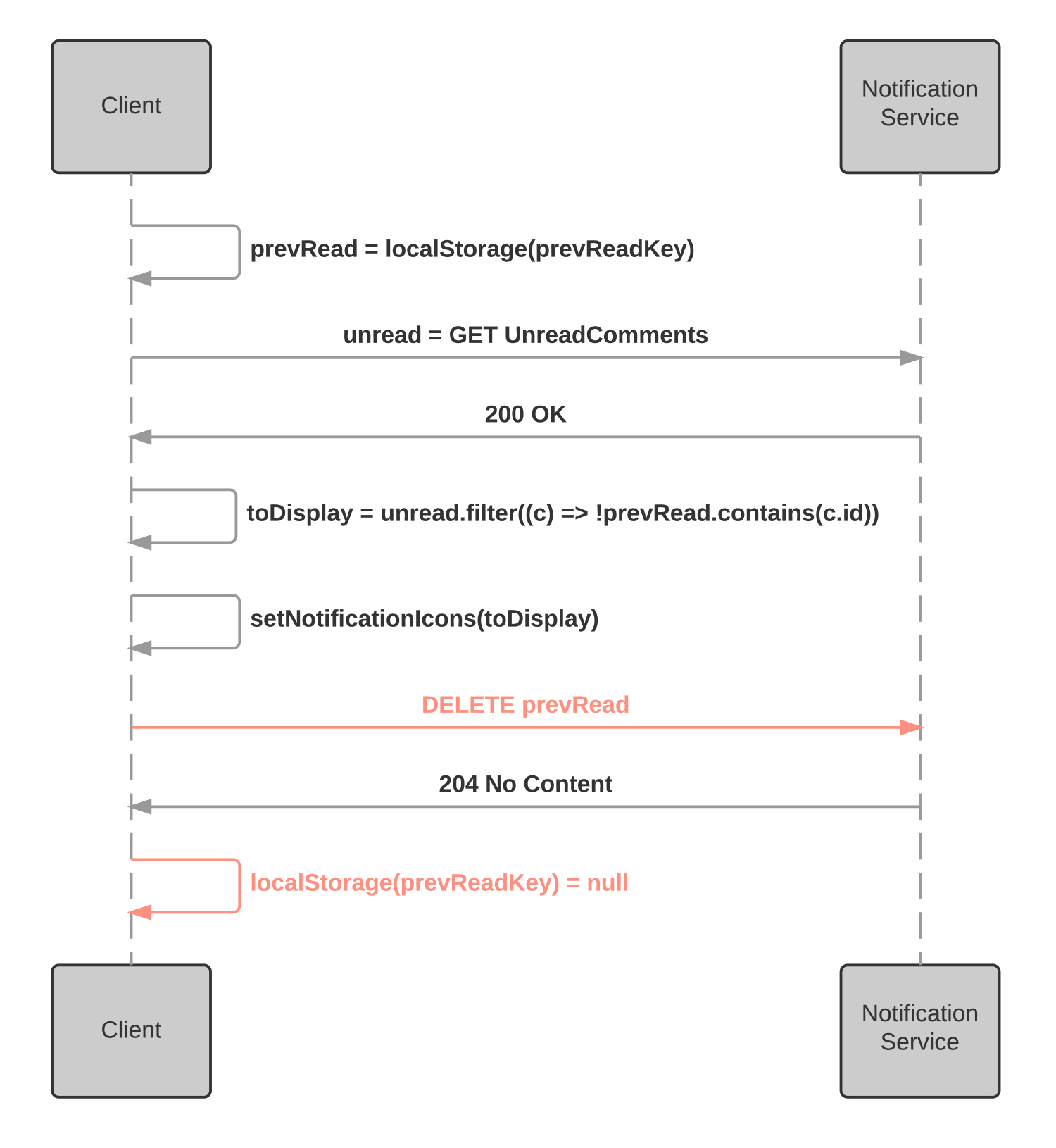
Since we don’t have to worry about a comment ever becoming unread after it is read, we can just delete any notifications for comments from the server once they’ve been read. On top of that, we can mark a comment as read as often as we want without worrying about unintended side effects, which means a MarkAsRead method is effectively idempotent: telling the server 100 times that comment 5QB6 has been read is exactly the same as telling the server once that comment 5QB6 has been read. We can take advantage of this by adding to our local storage the IDs of comments that have changed from unread to read, and then attempting to delete them from the server. If we get an acknowledgement, then we delete them from local storage.
A sequence diagram showing a notification being marked as seen
If we don’t get an acknowledgement, then we leave the comment IDs in local storage and attempt to notify the server again each time we load the document. On the client, we request a list of unread comments each time the document loads, but only mark comments as unread if they are both in the GET response, and not marked as read in local storage. The result is that the server only stores notifications for comments it thinks the client hasn’t read, and the client only stores notifications it thinks the server needs to delete.
Handling Hiccups
You may be wondering at this point where constraint #3 (“In the case of failure, err on the side of marking comments as unread”) comes into play. There may be cases where the delete attempt of a read comment notification fails, which means that only the local storage of the machine on which it was read knows that it has been read. While it will keep attempting to tell the server that the comment has been read, the user may open the document on another device before it successfully does so.
A comment was read on the laptop (left), but the server has not been notified. The workstation still shows it as unread (right)
This should not be a common occurrence, but we designed the system such that a second device will see all remaining notifications just as the original device did. Viewed from this perspective, it becomes difficult to imagine designing the system any other way. (For a more in-depth explanation of why we had to make the decision one way or the other, see The Two Generals Problem.)
Conclusion
Looking back, even though the upper bound of the storage requirement never changed from O(nm), we were able to pare down the storage cost in the common case quite a bit. We did so by capitalizing on certain properties of the problem, namely:
Notification data is user-specific. This allows us to store it outside the document, since no other user’s data (and, by extension, document data) will depend on it.
Notification data is Boolean and has a black-hole state. This allows us to delete entries instead of storing false values.
Both GET and DELETE are idempotent. This means that although we can never guarantee that the server and client have identical information, the client can send requests with impunity, without worrying about side effects.
We can reduce the storage requirement even further by adopting a policy of not showing notifications older than x days, which effectively reduces the n in O(nm).
In closing, when attacking a problem with known undesirable space complexity, keep in mind that while you can’t make the worst case outdo what the math says, you can make the common case small.
Check out notifications in Lucidchart.