Lucid Software is the leader in visual collaboration and work acceleration, helping teams see and build the future by turning ideas into reality. Its products include the Lucid Visual Collaboration Suite (Lucidchart and Lucidspark) and airfocus. The Lucid Visual Collaboration Suite, combined with powerful accelerators for cloud and process transformation, empowers organizations to streamline work, foster alignment, and drive business transformation at scale. airfocus, an AI-powered product management and roadmapping platform, extends these capabilities by helping teams prioritize work, define product strategy, and align execution with business goals. The most used work acceleration platform by the Fortune 500, Lucid's solutions are trusted by more than 100 million users across enterprises worldwide, including Google, GE, and NBC Universal. Lucid partners with leaders such as Google, Atlassian, and Microsoft, and has received numerous awards for its products, growth, and workplace culture.
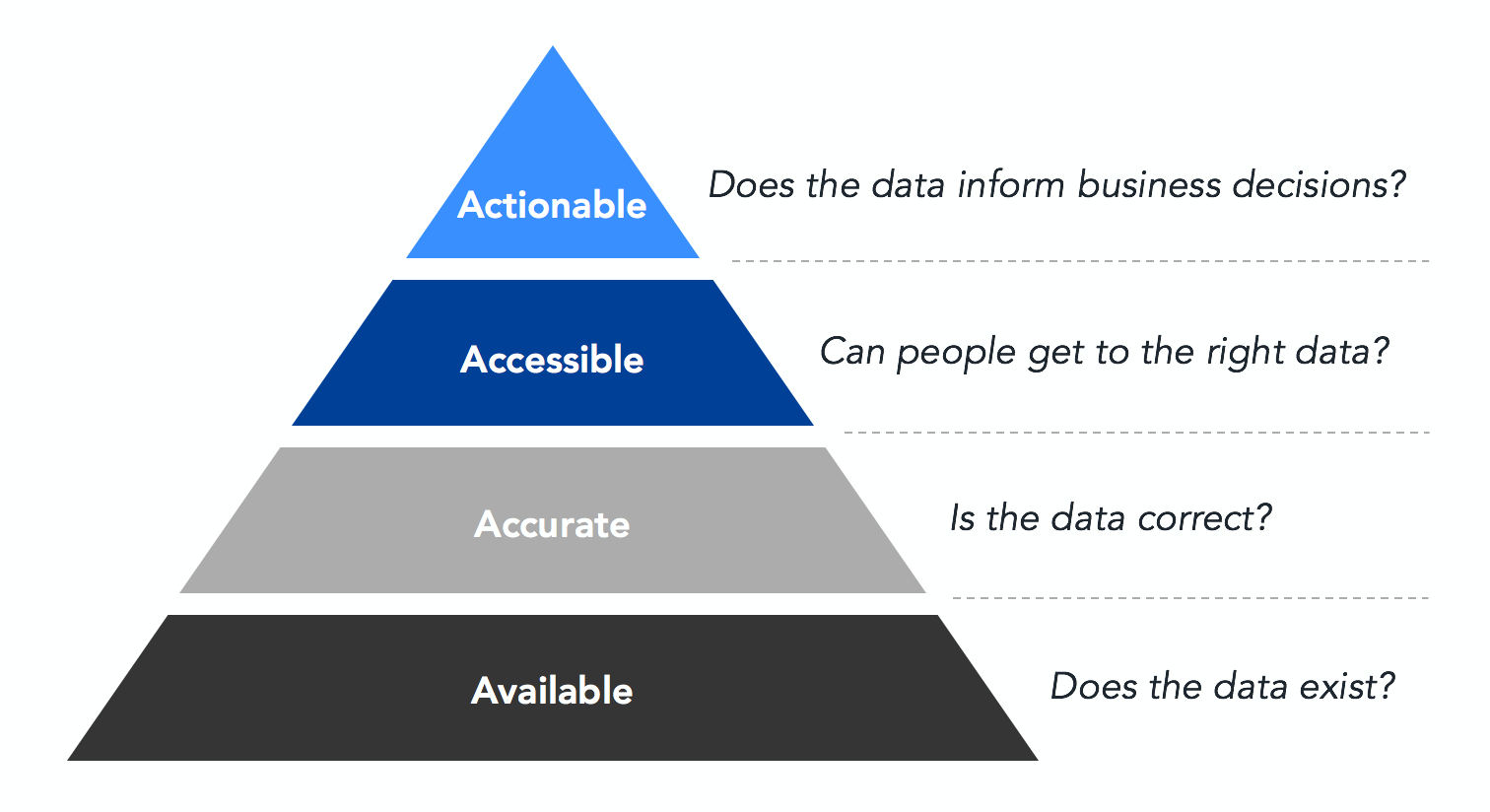
Here at Lucid, we rely on having accurate and timely data accessible to make informed business decisions. As we decide which features to build, how to best position ourselves in the market, and how to better serve our customers, we need to trust that our decisions are based on high-quality reporting. It's taken years of hard work and collaboration between our analytics and data infrastructure teams to build out a data pipeline that can provide high-quality, actionable data. In this blog post, we’ll talk about four key principles we’ve focused on to ensure the integrity of our data warehouse at Lucid: availability, accuracy, accessibility, and actionability.
Actionable analytics need to be built on a solid data foundation
Availability
Foundational to building a great data warehouse is data availability. A data warehouse has an availability problem if data that should be present is missing. Data might be entirely missing from the warehouse because it isn't being tracked at all or because the data pipeline isn't reliably collecting the data from its original location. At Lucid, our data teams have spent the last year improving our ETL infrastructure to ensure that all data is imported into our warehouse in a timely and correct manner.
There are many reasons that the data in a warehouse might lack availability. The simplest reason for unavailability is that the data we want isn't currently being collected; in this case, we might need to add a new column to our application databases or start triggering a new event. At Lucid, engineers reported that adding a new event to our analytics system required a lot of boilerplate code. To reduce the cost of adding a new event—and improve data availability of our warehouse—we created an internal tool for generating much of the necessary event boilerplate code.
Tracking Availability
Another key change we made to improve the availability of our data was to build an automated job that checks every table in our warehouse to make sure it has been updated in an appropriate time window (usually within 24 hours). This job runs every five minutes and triggers an alert to the data infrastructure team if a table has gone out of date. Once a table is up to date, the alert is automatically resolved. The status of each table is recorded in a table itself so we can build a dashboard that tracks the availability uptime of our warehouse.
Measuring our warehouse's availability provides us with much more insight into what the current state of our warehouse is at any given time. Merely triggering alerts when an ETL job experienced a failure was not sufficient because not all availability problems are directly connected to errors. For example, jobs that are turned off or running too slowly to stay caught up with our production data would not trigger errors, but still require engineering attention to fix. Thus, we found it critical to measure and track our actual expected outcomes.
Accuracy
Ideally, our data warehouse would be a paragon of truth. In practice, data accuracy issues are an ongoing reality and the only question is whether anyone will catch the problem before it causes cascading issues downstream. Several months ago, for instance, we noticed an inflated number of page views being reported through our analytics pipeline. After further investigation, we determined that a recent change made outside our team was causing a large number of duplicate pageviews for many users, and we were able to quickly fix the problem with a simple code change.
Database Discrepancies
Last year, we replaced AWS Redshift with Snowflake as our data warehousing solution. I noticed that the row counts between Snowflake and our application databases would sometimes be off. At that time, our ETL jobs would usually just select all data that was modified in a small time window and copy only that data over. However, this technique did not handle cases in which rows had been entirely deleted out of the application database or for which historical data had been erroneously dropped from Snowflake.
To work around mismatches in our databases, we added additional logic in our ETL jobs that counted the number of rows in the application databases and in Snowflake in a given time period. If a discrepancy existed, the job would simply delete the data in Snowflake for that time period and re-copy the data from production. By having the job perform retroactive corrections, we increased our assurance that the data in Snowflake actually matched what was in the application databases.
Accessibility
Even once we had made our data available and accurate, decision-makers still struggled to access the data. Making data accessible requires more than just giving someone permissions to access the data they care about. In order to make a warehouse fully accessible, individuals must also be able to manipulate and correctly query data in the warehouse.
At Lucid, many employees technically had permissions to access data in the warehouse through the online SQL interface, but not all of those with permissions had a strong SQL background. To make the data more accessible to these individuals, we built custom tooling and provided additional training.
Custom Tooling
We've begun building internal applications to improve the experience of using the most widely relevant and frequently accessed data at Lucid. For example, in order to make AB-testing more consistent and user-friendly, we are building a web application that automates much of the statistical legwork necessary to run a successful test. This application will allow us to make feature decisions for our products more quickly and accurately than before while saving analysts and product managers hours of tedious manual work.
We're also developing an application that will allow employees to view a real-time stream of events that have been recorded for their current session. This will greatly aid in the planning, implementation, and validation process for adding new analytics into our products and will also eliminate much ambiguity about which events are triggered when.
Provide Training
Here at Lucid, employees are given numerous opportunities to improve their skills and knowledge in a variety of areas, both technical and non-technical. As part of our initiative to improve the accessibility of data at Lucid, we periodically provide a 6-week SQL course, available to any interested employees. Employees that complete the SQL course become better qualified to explore the data, answer critical questions, and make more informed decisions for their teams. This individual empowerment has led to improved team and company productivity.
Actionability
Even if accurate data exists in the warehouse and is accessible to all interested parties, individuals may still be unsure of how to accurately interpret the data available to them. This means that the data is dead in the water, completely useless for providing business insights. We found that in most cases, documentation and the aid of some custom tools can help with correctly interpreting or visualizing data from our warehouse.
Documentation of our data is critical for making data actionable. Without the appropriate documentation, consumers of the data will find it difficult to find and use the data that is available to them. We use DBT (Data Build Tool) as part of our data transformation and modeling process. DBT has a documentation feature which allows us to translate special comments from the modeling code into a searchable website which we publish on our intranet as part of an automated build process. Because of the documentation feature, all employees can more easily understand and take action on the data resources available to them.
Conclusion
Actionable analytics need to be built on a solid foundation of data integrity. As we’ve improved the integrity of our data warehouse, we’ve been able to make more informed decisions about our product direction at Lucid and move more quickly as an organization. By addressing each of the principles of data integrity we’ve discussed today (availability, accuracy, accessibility, actionability), you will quickly be on your way to building a successful, data-driven organization.
How have you improved the integrity of your data warehouse? Let us know in the comments below!

 Actionable analytics need to be built on a solid data foundation
Actionable analytics need to be built on a solid data foundation