
Lucid’s Strategy & Analytics team has the main responsibility and objective of helping our internal stakeholders achieve business impact. The way we accomplish this is through a combination of strategic analyses (providing data-driven recommendations on key issues) and data modeling (collecting and transforming data to make it clean, accurate, useful, and accessible to the rest of the company).
Charles Babbage, the 19th-century English polymath widely considered to be the “father of the computer,” once said that “errors using inadequate data are much less than those using no data at all.” While this statement may be true for inadequate or even insufficient data, could we say the same for making decisions based on plain incorrect data instead? What if we failed to address a creeping downward trend in revenue due to inflated revenue numbers—or invested millions of dollars and thousands of hours on the wrong features due to miscategorized customers?
What data validation is—and why you should care
You can imagine how big of an issue making strategic decisions or inferences using such data would be. At best, your information will be incomplete; at worst, you’ll end up severely misguided. These dire consequences can be caused by a dangerous gap in our decision-making process: a lack of data validation. Regardless of whether you are the one actually manipulating the data, understanding general principles of data validation will enable you to methodically think through the numbers and effect positive and meaningful impact.
Put simply, data validation means ensuring your data is free of errors. Rather than just assuming our queries1 or spreadsheet formulas will yield exactly what we intend, we need to test those assumptions and address any observed or potential issues in our output. Note that this will not necessarily make your data perfect. The “garbage in, garbage out” dogma still applies, meaning that if your source or logic is inherently flawed, any downstream dependencies2 will be just as (or potentially more) problematic.
| Key terms | |
| Query | Code used to modify or pull data from a database, usually written in SQL3 |
| Downstream dependency | Elements such as data tables or online dashboards that are directly (one step “away”) or indirectly (two or more steps “away”) connected to another element. For example, a sales dashboard that is powered by a spreadsheet is that spreadsheet’s downstream dependency |
| SQL | Structured Query Language, a programming language designed for data management, transformation, or retrieval |
Common error types
Let’s talk about some of the typical issues we see and best practices we at Lucid have developed regarding data validation. While this post will focus primarily on issues seen when working with SQL, these principles should translate to most languages and tools you may use in your own data environment.
We most often come across three main types of errors as we pull and transform data:
- Compilation errors
- Runtime errors
- Logical errors
Compilation errors happen when a compiler (e.g., the Snowflake SQL compiler) fails to convert your code into instructions that can be executed by a computer. The most common compilation errors are syntax errors:

Runtime errors occur after your code successfully compiles and starts running. These errors are commonly referred to as “bugs” in a program. Examples include attempting a division by 0, mismatching data types, etc.
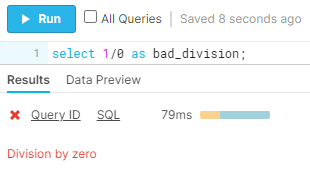
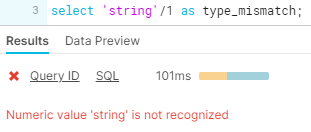
Logical errors result from logic in your code that produces a different outcome from what is intended. Common examples include improper join types or conditions resulting in duplicate rows, incorrect boolean logic, incorrect aggregations, mishandled NULL values, overlapping or missing case statement classifications…the possibilities are endless! And that’s not great.
Resolving compilation and runtime errors is generally straightforward due to descriptive error messages surfaced by the compiler or platform you’re using. By contrast, logical errors will neither prevent your code from running nor notify you of any potential issues. This makes catching and addressing them extremely challenging, earning them the title of “the most insidious type of error,” as our director would say. Let’s look next at some ways through which you can not only anticipate but also test for logical errors in your data.
Anticipating and testing for logical errors in your data
We all make assumptions when working with data:
“This field doesn’t have any NULL values.”
“These categories are mutually exclusive and collectively exhaustive.”
“My output doesn’t have any duplicate rows.”
However, if we want to ensure our work is as error-free as possible, we first need to identify these assumptions and methodically test them. Doing so will allow us to prepare for potential issues that may sneak up on us and resolve them before they make it into our final results. Consider the following questions as you seek to identify what could potentially cause your output to be incorrect:
- Does my output even make logical sense? Are my numbers realistic?
- Are the unique keys in my table actually unique?
- How am I handling NULL values?
- Am I referencing single sources of truth or derived/downstream tables?
- Would inaccuracies in my logic be noticeable in my output?
- Are there any downstream dependencies on my output that could be negatively affected by changes?
Once you have identified any areas for concern, it is then time to test and validate your data. A general tip is to try coming up with a few hypotheses first: What values would you expect never to be NULL? What values should never have any duplicates? If you manually calculate an average, does the automated output match your calculation? Use anything you know to be true or can verify in some other way to ensure accuracy.
As that practice suggests, data validation is far easier if you follow what is considered to be the “first commandment” for data professionals: know thy data. If you know what the data should look like, validating it and catching issues becomes significantly easier. Refer to internal or external documentation, your own knowledge and experience, and even domain experts in order to deepen your understanding of the data itself, its context, and application.
Similarly, you should strive to be intimately familiar with the “grain” of the table(s) you are working with. A table’s grain is defined by a set of 1 or more fields that make each row unique. For instance, if you have a table that should be unique by customer, then your grain-defining field should be “customer_id” or a similar primary key. Misunderstanding or not knowing a table’s grain can severely impact your output, particularly when you attempt to join different tables. Make sure to check whether your table is actually unique on its grain-defining field(s) by testing whether there are any duplicate customer IDs, for example. When performing joins, be careful not to miss any grain-defining fields in your join conditions, as that could introduce duplicates in your output.
NULL values deserve extra attention, as they can be affected by not only the data values themselves but also on the functions used on relevant fields. For instance, most aggregation functions—such as max(), sum(), and avg()—will ignore NULL values when performing calculations; however, comparison operations (e.g., >, =) will return NULL if any of the operands are NULL:
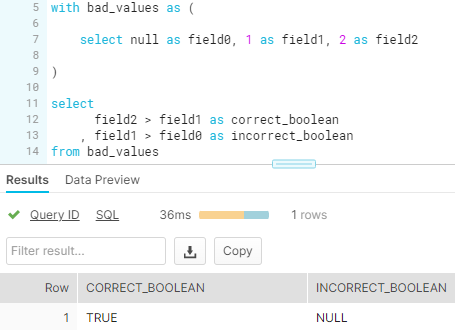
NULL values also rely on how you want to address them. In some cases, you might want to make sure you are counting every NULL value as 0 instead; in other cases, you might actually prefer for a field to stay NULL. Think through what is the most appropriate way to handle NULL values based on your end goal in using that data.
Other logical errors can be caught by a) coding with data validation in mind and b) adding error flags or tests in your code. The KISS (“keep it simple, silly”) principle is one of your most powerful tools in validating your data, and will enable anyone else that may look through your work to easily follow your logic as well. It may be tempting to try to eliminate as many lines as possible and perform all needed transformations or calculations in a single step. Nevertheless, remember that as long as your code is not unnecessarily redundant, it is better to manipulate data in sequential stages so that you can quickly validate each step. Lines of code are free, but time is expensive!
Similarly, you can add error flags or tests to easily identify where something went awry. While using error scripts or automated testing may not be feasible every time, you can still implement simple checks in your code, such as explicitly calling each possible scenario in a case statement and using the “else” portion to return “error” so that you can immediately verify whether your classifications were incorrect.
What comes next
After all this testing, it may be difficult to recognize when enough validation is enough. In such moments, remember that data will almost always be imperfect and that you will eventually reach a point of diminishing returns. Use your best judgment and don’t hesitate to collaborate with others in determining what level of “error tolerance” would be appropriate for your or your organization’s needs. It will then be a matter of choosing “good enough” versus “perfect.” We hope that as you apply these principles and test your main assumptions, you will go from using incorrect or inadequate data to using useful data instead.
Written by Gregory Shibuta with contributions from Paul Detwiler, Remy Millman, and Weston Rowley