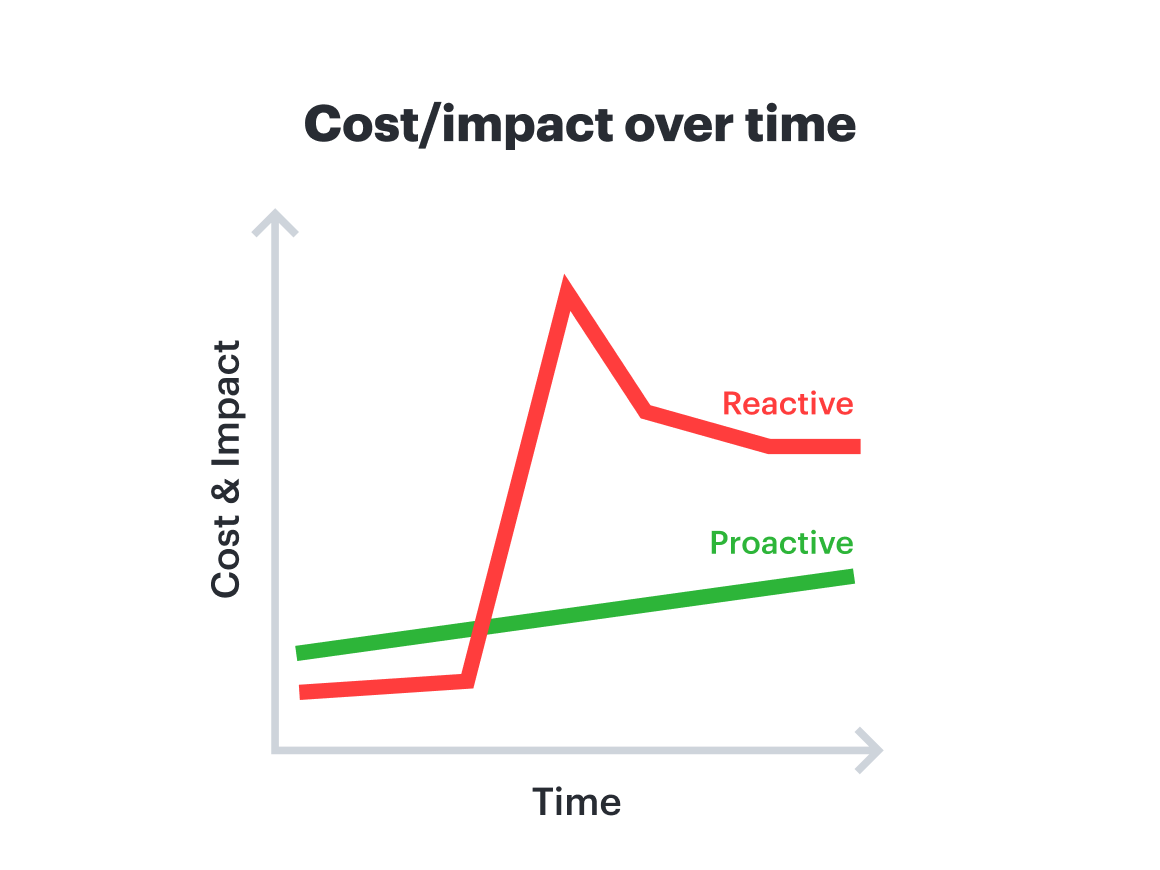
Consequence #1: Lost time and momentum
In reactive IT approaches, the only way your team can learn that there are problems is through reporting and alerts. This often leads to excessive reporting, which wastes IT teams' time on potentially low-value tasks. It also means lost time needed to innovate and stay ahead of the competition.
It’s not only impossible to respond to every single request, but it’s super expensive compared to proactive IT support. It also makes prioritization much more difficult because IT teams aren’t in the driver’s seat and can’t get a bird’s-eye view of demands and the best way to allocate their resources.
Consequence #2: Wasted money
If you wait for a report that tech isn’t working properly, you’ve already lost productivity from the employee who was trying to use it. Every minute you don’t catch a bug or performance issue, the bill for fixing exponentially increases. And as the problem becomes more concerning over time—such as with a data leak that can cause increasing damage by the second—the cost to fix it jumps about 50x at each step it moves down the pipeline. A vulnerability that costs $100 to fix in design can easily cost $5,000 once it reaches production. Proactively identifying problems saves money in this way.
Consequence #3: Increased vulnerability gap
“Your competitive edge dissolves when you’re reactive.”
—Nathan Cooper, Director of Information Security, Lucid
Reactive IT puts your most critical resources at risk. Every minute a system flaw or intrusion goes undetected is an additional minute that an unauthorized actor has to map your network and exfiltrate proprietary data. This doesn’t just increase the technical complexity of the fix, it leads to a direct loss of customer trust.
Examples of proactivity
So, what does proactivity actually look like in practice?
Example #1: Hardware failure
Reactive approach: You wait for a “disk failure” alert. But by then, the server is down, data is at risk, and your team is scrambling for backups so nothing is lost or leaked.
Proactive approach: By monitoring drive health metrics, such as S.M.A.R.T. metrics, you can identify that a drive is likely to fail in the next month. You swap it out during a scheduled maintenance window. Neither customers nor employees even notice, and all issues are prevented.
Example #2: Data breach
Reactive approach: You discover an unauthorized user account that has accessed sensitive data. At this point, you have no idea how long it’s existed or what exactly has been leaked. Your team is forced into an emergency containment mode to prevent further damage. You shut down servers, reset passwords, and are then tasked with explaining the lapse to stakeholders and customers, rebuilding trust, and mitigating damage.
Proactive approach: Instead of waiting for an alert, your systems automatically flag vulnerabilities. You use real-time monitoring to spot concerning user behavior and can automatically lock accounts before they access sensitive data.
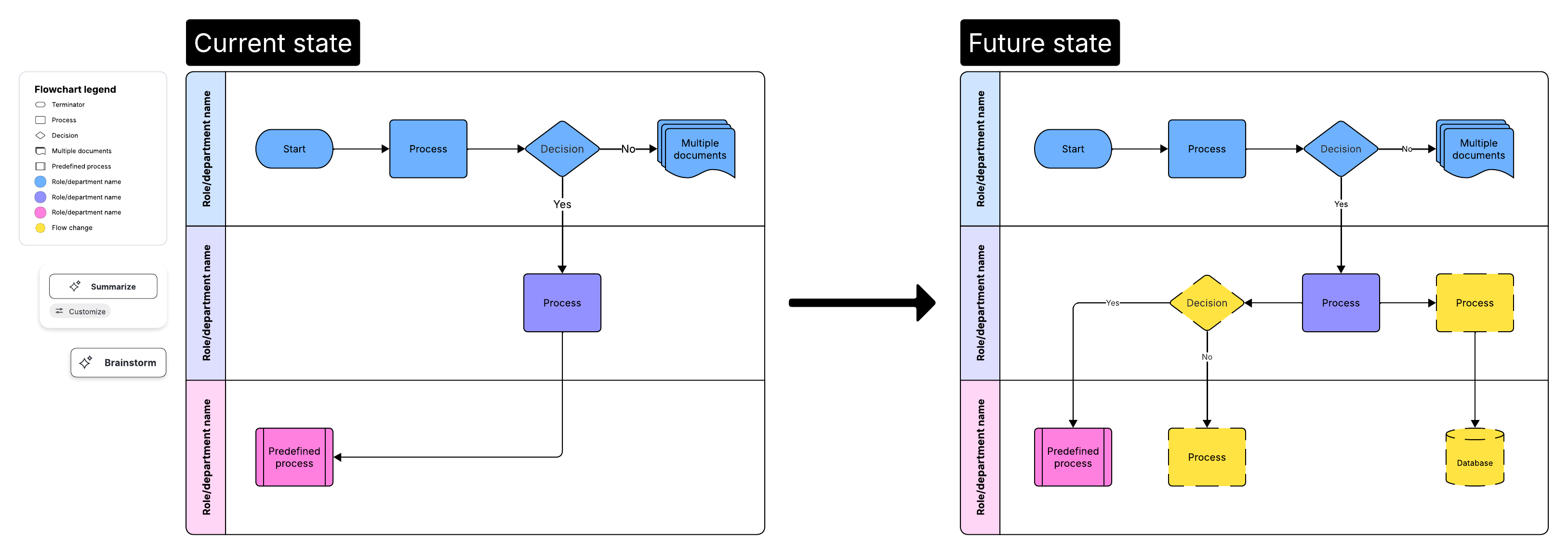
Keys for moving from reactive to proactive IT management
Shifting from a reactive to a proactive stance requires a structured approach. These four pillars serve as the foundation for that transition:
1. Standardize infrastructure hygiene
Proactive IT requires a foundation of uniformity. By establishing standard hardware and ensuring all systems, from company laptops to servers, run the same updated software, you significantly reduce the variables that lead to failure. Treating infrastructure as standardized, replaceable resources (sometimes referred to as the “cattle vs. pets” philosophy) allows for automated configuration management and infrastructure as code (IaC). This simplifies the enforcement of security requirements, such as SSO and SCIM, and enables more effective centralized auditing.
Cooper suggests, “To maintain this hygiene, start with a comprehensive audit of your existing environment. By grouping resources by purchase date or firmware version, you can create a visual timeline to identify exactly which assets are nearing their end-of-life and may be vulnerable. This allows you to formalize a refresh schedule and stay ahead of hardware degradation.”