Decision trees in machine learning and data mining
A decision tree can be used to help build automated predictive models, which have applications in machine learning, data mining, and statistics. Known as decision tree learning, this method takes into account observations about an item to predict that item's value.
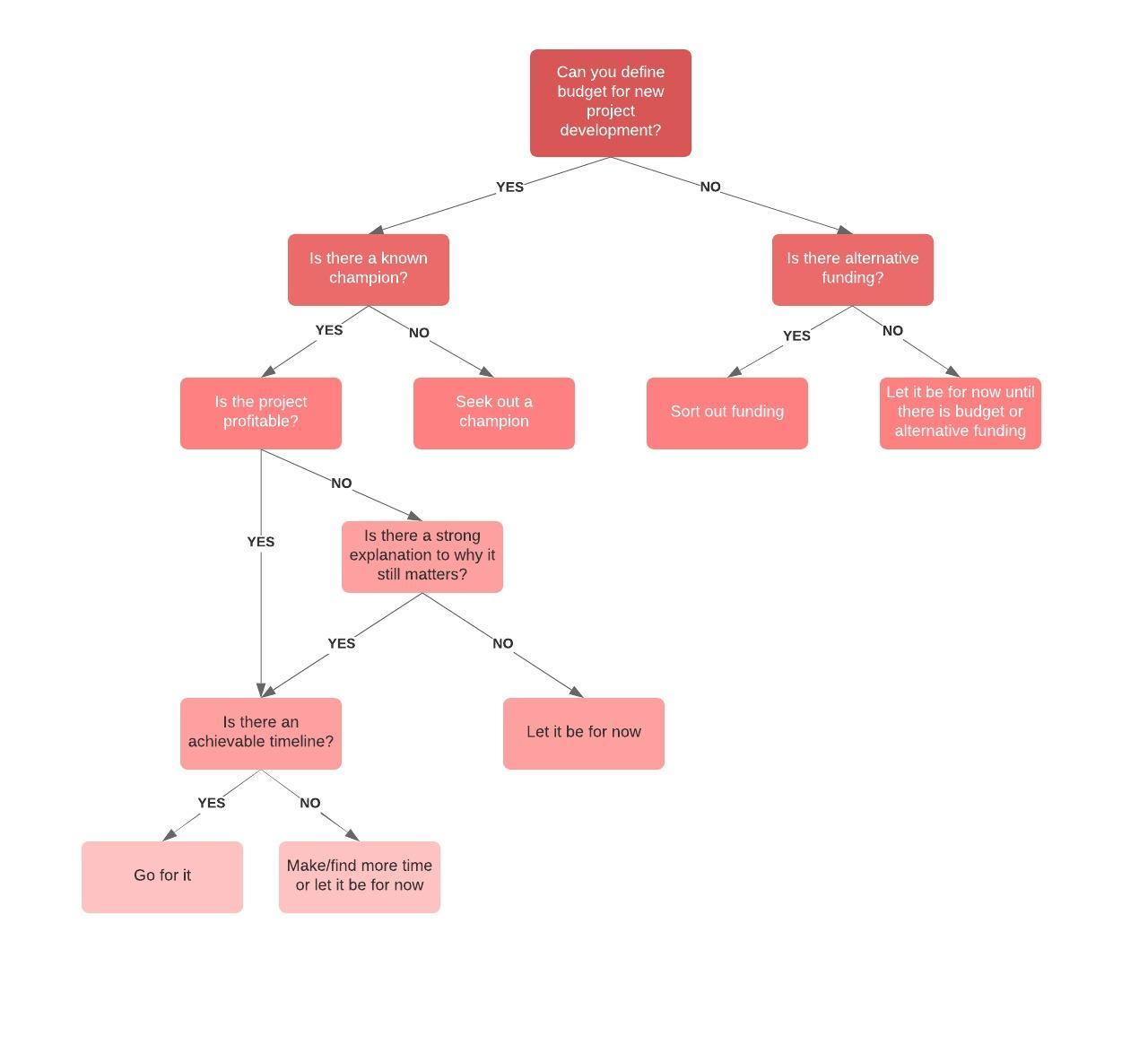
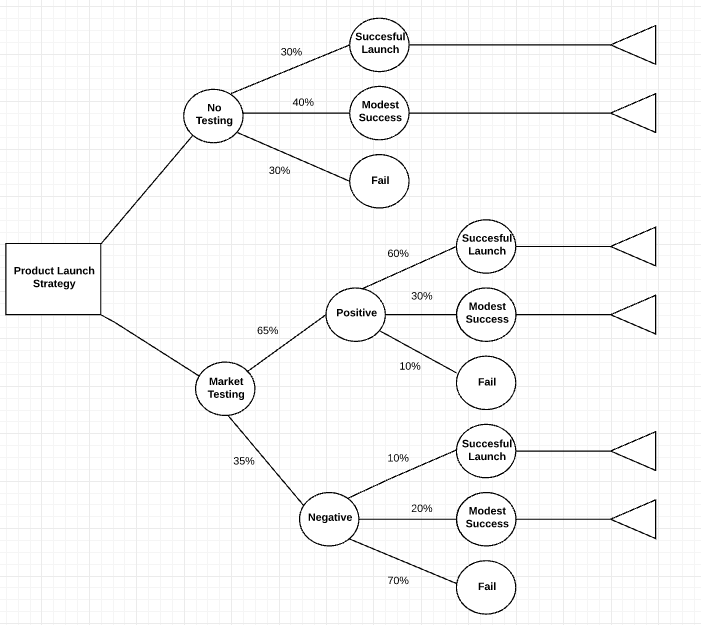
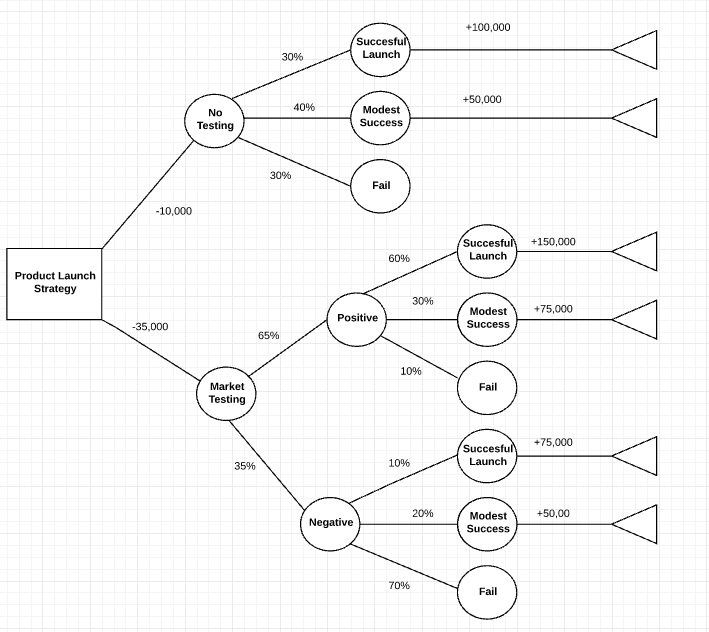
In these decision trees, nodes represent data rather than decisions. This type of tree is also known as a classification tree. Each branch contains a set of attributes, or classification rules, that are associated with a particular class label, which is found at the end of the branch.
These rules, also known as decision rules, can be expressed in an if-then clause, with each decision or data value forming a clause, so that, for example, "If conditions 1, 2, and 3 are fulfilled, then outcome x will be the result with y certainty."
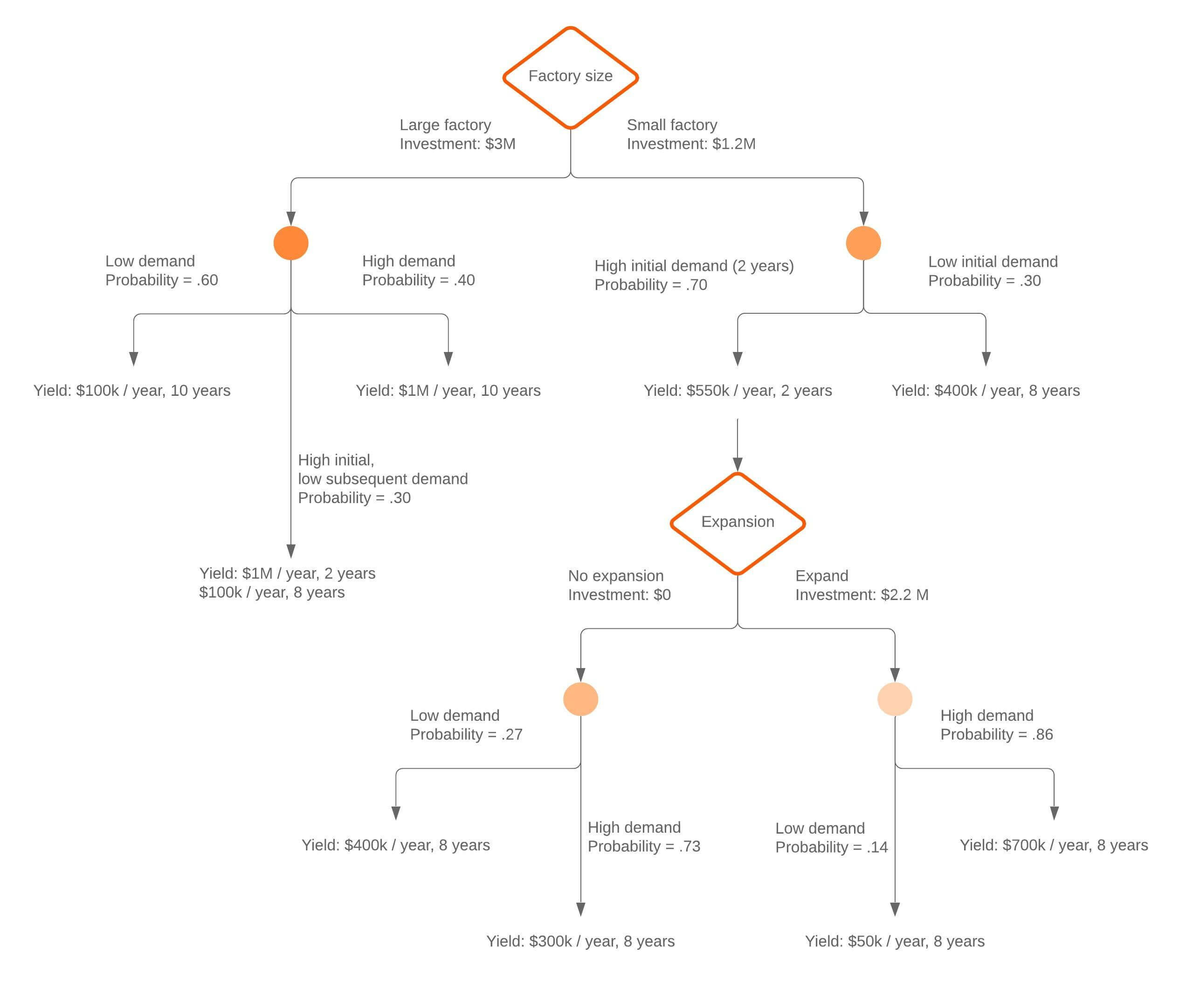
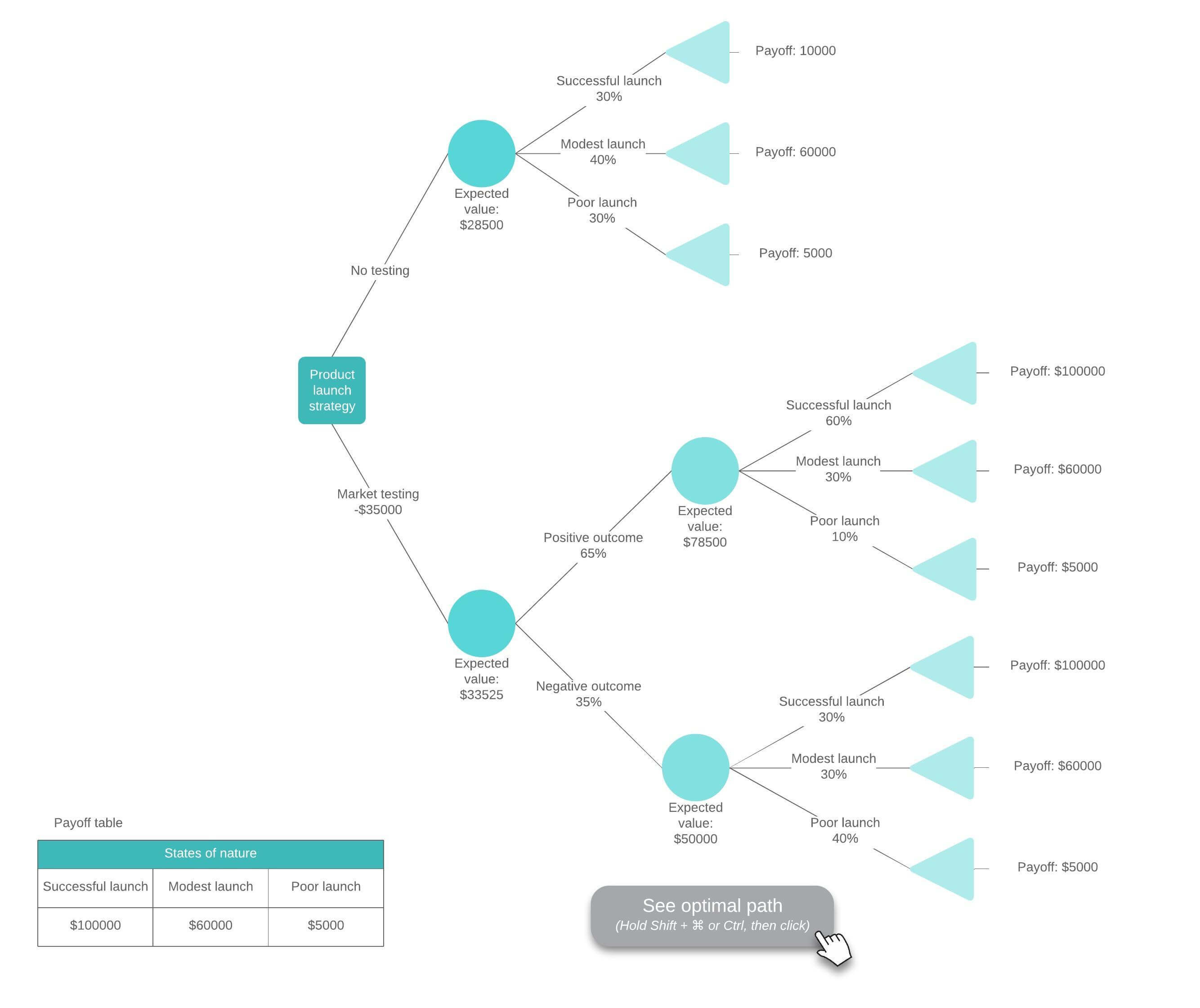
Each additional piece of data helps the model more accurately predict which of a finite set of values the subject in question belongs to. That information can then be used as an input in a larger decision-making model. Sometimes the predicted variable will be a real number, such as a price. Decision trees with continuous, infinite possible outcomes are called regression trees.
For increased accuracy, sometimes multiple trees are used together in ensemble methods:
- Bagging creates multiple trees by resampling the source data, then has those trees vote to reach consensus.
- A Random Forest classifier consists of multiple trees designed to increase the classification rate
- Boosted trees that can be used for regression and classification trees.
- The trees in a Rotation Forest are all trained by using PCA (principal component analysis) on a random portion of the data
A decision tree is considered optimal when it represents the most data with the fewest number of levels or questions. Algorithms designed to create optimized decision trees include CART, ASSISTANT, CLS and ID3/4/5. A decision tree can also be created by building association rules, placing the target variable on the right.
Each method must determine the best way to split the data at each level. Common methods for doing so include measuring the Gini impurity, information gain, and variance reduction.
Using decision trees in machine learning has several advantages:
-
The cost of using the tree to predict data decreases with each additional data point.
-
Decision trees work for either categorical or numerical data.
-
They can model problems with multiple outputs.
-
They use a white box model (making results easy to explain).
-
A tree's reliability can be tested and quantified.
-
Decisions tend to be accurate regardless of whether they violate the assumptions of the source data.
But they also have a few disadvantages:
-
When dealing with categorical data with multiple levels, information gain is biased toward attributes with the most levels.
-
Calculations can become complex when dealing with uncertainty and many linked outcomes.
-
Conjunctions between nodes are limited to AND, whereas decision graphs allow for nodes linked by OR.
In data work, you’ll most commonly encounter two broad decision-tree diagram types—classification and regression—each suited to different kinds of outputs. Both are valuable systems, but they work a bit differently and have their own distinct uses.
With classification trees, you can sort objects, units, outcomes, and groups into categories. You can set up branches with characteristics that facilitate classification and provide at-a-glance delineation among categories. For example, you can use a classification tree with data mining to help sort different types of outcomes into categories.
Regression trees, rather than helping with classification, help with prediction. A regression tree uses continuous variables—which are obtained through measurement—to select branches (or nodes). In other words, you might use a regression tree to sort outcomes based on their probability of happening.